この記事では、pandasライブラリでcsvファイルを読み込む方法を具体的に紹介します。
サンプルコードを見ながら、サクサク処理を試せますのでぜひ活用してみて下さい。
ライブラリのインストール
はじめにpandasライブラリをインストールしましょう。
ターミナル(mac)もしくはコマンドプロンプト(Windows)で以下を実行します。
pip install pandas最終行に「Successfully installed 〜〜〜」と表示されていればインストールは成功です。
csvを読み込み(read_csv())
pandasライブラリを使ったcsvファイルの読み込み方法を解説します。
pandasライブラリには、read_csv()というcsvファイル読み込みメソッドが用意されています。
import pandas as pd
# sample.csvというcsvファイルを読み込んでDataFrameに格納
df = pd.read_csv("sample.csv")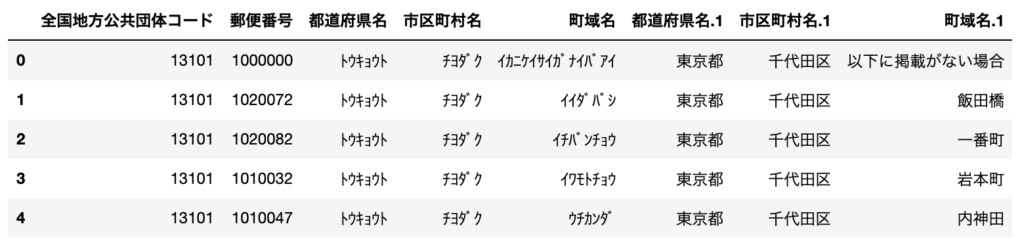
読み込んだcsvファイルをpandasのDataFrameオブジェクトにすることができます。
ヘッダーの指定(header)
読み込むcsvファイルのどの行をヘッダー(header)とするか指定することができます。
引数headerに、ヘッダーに使用した行番号(整数)を指定しましょう。
Noneとした場合はどの行も指定せず、列番号にインデックスが振られて各値がヘッダーになります。
import pandas as pd
df = pd.read_csv("sample.csv", header=None)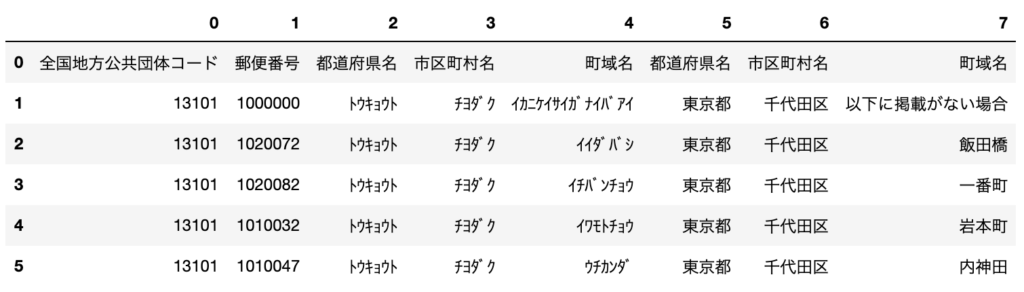
read_csv()メソッドの引数headerをNoneとすると列のインデックスが列名となります。
引数headerに2(3行目)を指定してみましょう。
import pandas as pd
df = pd.read_csv("sample.csv", header=2)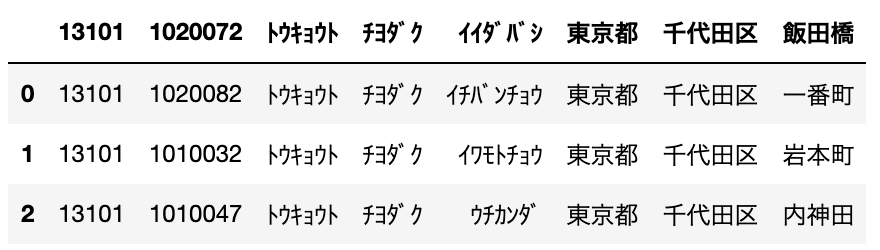
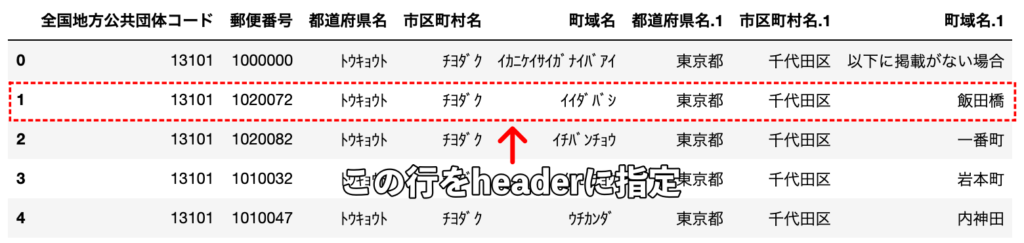
ヘッダーをデータの3行目(indexは2)を指定するとそれ以降の行がDataFrameに格納され、上の行は無視されます。
インデックスの指定(index_col)
読み込むcsvの行インデックスを指定することができます。
引数index_colに行名にしたい列インデックス番号(整数値)を指定しましょう。
デフォルトはNoneが指定されており、行インデックスがそのまま行名となっています。
import pandas as pd
# 行のインデックスを指定して読み込み
df = pd.read_csv("sample.csv", index_col=0)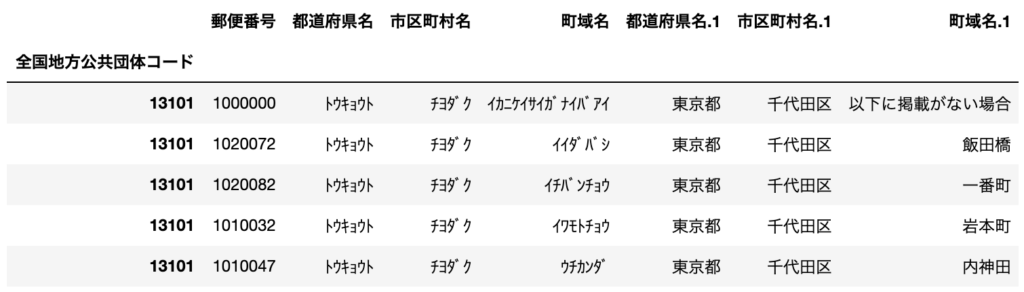
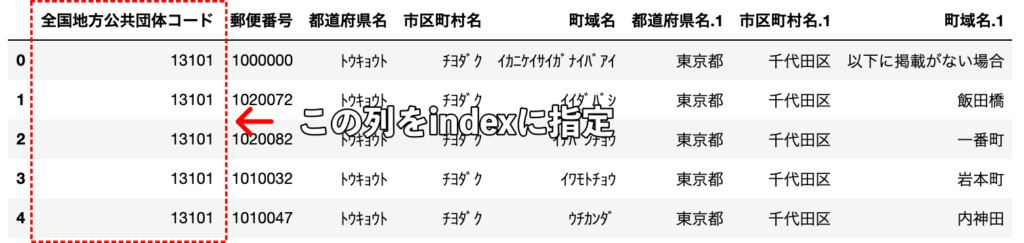
行インデックスがcsvの1列目(インデックスは0)となっていることがわかります。
特定の列だけを読み込み(usecols)
csvファイルの特定の列だけを選択してDataFrameに読み込むことができます。
引数usecolsに読み込みたい列インデックス番号をリスト型にして指定しましょう。
import pandas as pd
# 2列目、4列目だけをDataFrameに読み込み(indexは1, 3)
df = pd.read_csv("sample.csv", usecols=[1, 3])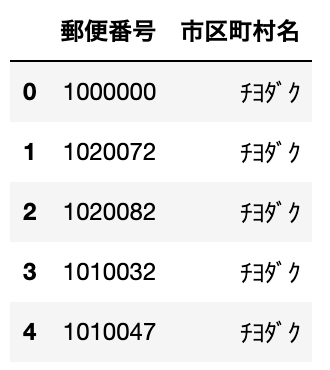
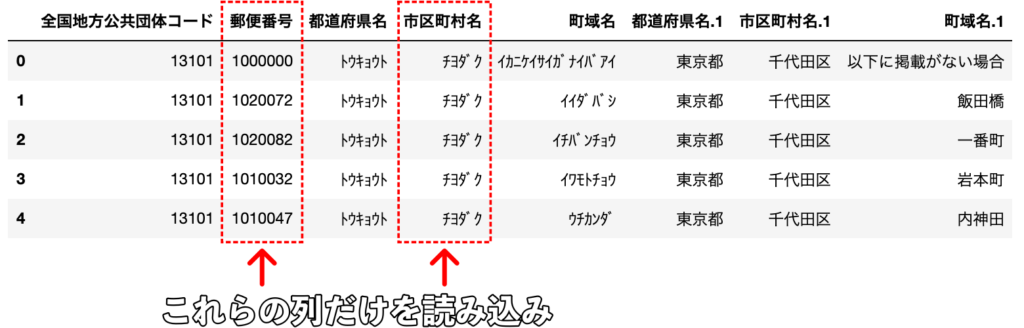
指定した列のみDataFrameに格納されていることがわかります。
1列だけ読み込む場合でも引数usecolsはリスト型で指定しましょう
import pandas as pd
# 3列目だけをDataFrameに読み込み(indexは2)
# df = pd.read_csv("sample.csv", usecols=2) # ← リストにしないとエラー(ValueError)が出る
df = pd.read_csv("sample.csv", usecols=[2]) # ← OK行をスキップして読み込み(skiprows)
先頭から任意の行数スキップ
csvファイルから先頭の任意の行数スキップして読み込むことができます。
引数skiprowsにスキップしたい先頭からの行数を整数型(int型)で指定しましょう。
import pandas as pd
# 先頭の2行をスキップして3行目から読み込み
df = pd.read_csv("sample.csv", skiprows=2)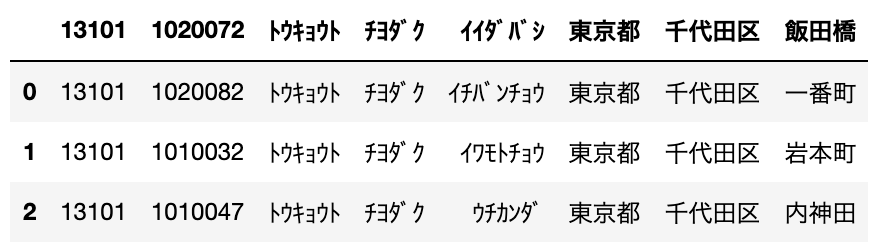

上の先頭2行がスキップされ、3行目からDataFrameに読み込まれていることがわかります。
指定した特定の行だけをスキップ
先頭からの行数ではなく、指定した特定の行だけをスキップして読み込むこともできます。
引数skiprowsにスキップしたい特定の行インデックス番号をリスト型にして指定しましょう。
import pandas as pd
# 2行目と4行目をスキップして読み込み(indexは1, 3)
df = pd.read_csv("sample.csv", skiprows=[1, 3])
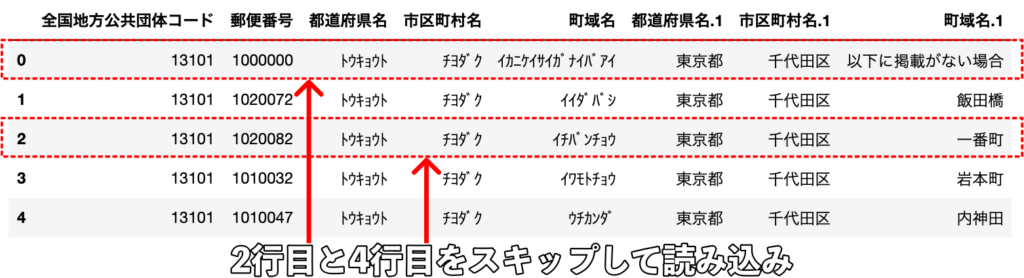
末尾をスキップして読み込み(skipfooter)
csvファイルの末尾を任意の行数スキップして読み込むことができます。
引数skipfooterにスキップしたい末尾からの行数を指定しましょう。
import pandas as pd
# 末尾2行をスキップして読み込み
### 実行環境によっては警告文が出るため、引数engine="python"を指定
df = pd.read_csv("sample.csv", skipfooter=2, engine="python")
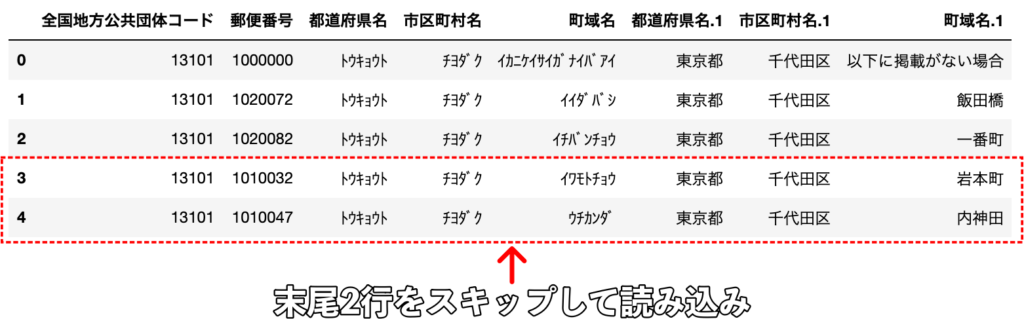
末尾2行分をスキップして読み込まれていることがわかります。
引数skiprowsを使用する場合、実行環境によっては警告文が出る場合があるため、同時に引数engineを明示的に"python"と指定しています。
文字コードを指定(encoding)
読み込むcsvファイルの文字コードが適していないとエラーが出ることがあります。
指定と異なる文字コードで作成されたcsvファイルもあるので、文字コードの指定には注意が必要です。
以下のような文字化けが発生したり、エラーで読み込めなかったりすることもあります。
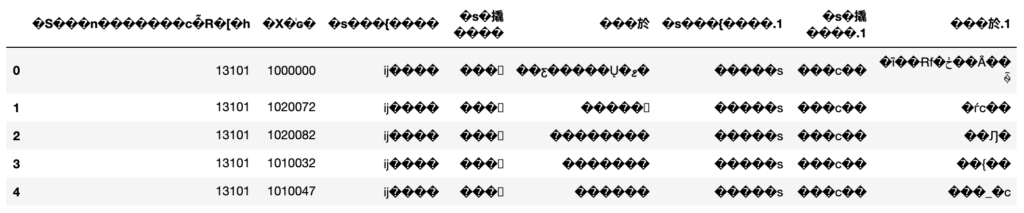
そうした場合は、read_csv()メソッドの引数encodingを指定してみましょう。
import pandas as pd
# 文字コード(ecoding)を指定してcsv読み込み
df = pd.read_csv("sample.csv", encoding="shift_jis")文字コードを指定することで文字化けが解消しましたね。
よく使用される日本語文字コードの一覧を載せておきますが、基本的にはshift-jis、utf-8の2種類がほとんどです。
まとめ
今回はcsvファイルをpandasのDataFrameに読み込む方法を具体的にご紹介しました。
大量のデータを整理・分析する際はpandasライブラリが非常に有効ですので、ぜひ活用してみてください。