
本ページには PR が含まれます。

Twitterのタイムラインから特定ワードだけを検索したいなぁ
どうやればいいんだろう…?
今回はPythonでTwitterタイムラインから指定したキーワード検索を検索・抽出する方法をご紹介します。
- 特定キーワードを使うユーザの傾向を知りたい方
- トレンドやバズりやすいキーワードを分析したい方
- Twitter運用・分析を効率化したい方
サンプルコードを見ながらサクサク処理を試せるので、ぜひ参考にしてみてください!!
なお、Twitter APIの利用には事前登録が必要です。
↓の記事でわかりやすく解説しているので、ぜひ参考にしてみてください。

Twitter APIの登録が済んだら、さっそくTwitterタイムラインのキーワード検索を実装していきましょう!!
ライブラリのインストール
はじめに今回の実装に使用するライブラリをインストールします。
Twitter APIのユーザ認証に利用するのがOAuth認証です。OAuth認証をカンタンに行える「requests_oauthlib」ライブラリをインストールしましょう。
コマンドプロンプト(Windows)もしくはターミナル(macOS)で以下を実行します。
pip install requests_oauthlibコンソールに「Successfully installed 〜〜〜」と表示されていればインストールは成功です。
OAuth認証でアカウントにアクセス
OAuth認証とは
OAuthは、ユーザアカウントのアクセストークンを使ってTwitter(サービス)へのアクセス権限をアプリに与え、 APIのスムーズな利用を可能にする認証規格です。
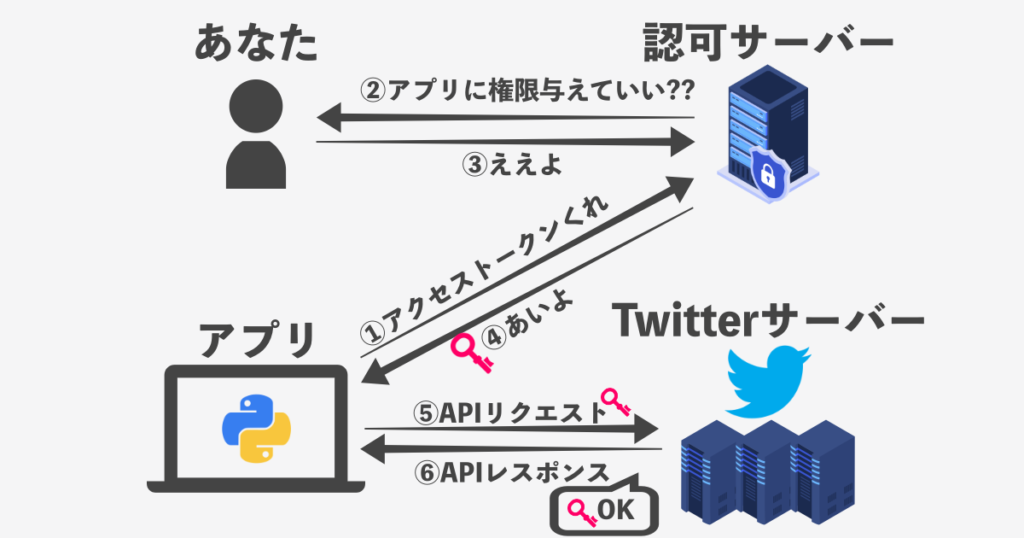

Twitter APIをより安全に利用するため、ユーザはアクセストークンを利用してTwitterサーバーと情報のやりとりを行います。
OAuth認証の実装 (サンプルコード)
インストールしたrequests_oauthlibライブラリを使ってPython自分のTwitterアカウント権限を通してみましょう。
# ライブラリのインポート
from requests_oauthlib import OAuth1Session
# キーの設定
API_KEY = "あなたのAPI Key"
API_KEY_SECRET = "あなたのAPI Key Secret"
ACCESS_TOKEN = "あなたのAccess Token"
ACCESS_TOKEN_SECRET = "あなたのAccess Token Secret"
# OAuth認証を通して「twitter_oauth」という変数に格納
twitter_oauth = OAuth1Session(API_KEY, API_KEY_SECRET, ACCESS_TOKEN, ACCESS_TOKEN_SECRET)タイムラインから指定キーワードで検索
さっそく指定したキーワードを含むツイートを検索してみましょう。
使用するAPIリソースURL
ツイート検索で使用するAPIリソースは以下のURLです。
request_search_url = "https://api.twitter.com/1.1/search/tweets.json"APIリクエストに関する情報
| レスポンスのフォーマット | jsonフォーマット |
| 認証が必要か | 必要 |
| 上限リクエスト回数 / 15分 | 450 |
APIリクエストには上限回数があります。
短時間に大量のリクエストを送信するとサーバーに負荷がかかってしまうため、なるべく間隔を空けましょう。
サンプルコード
import json
from requests_oauthlib import OAuth1Session
API_KEY = "あなたのAPI Key"
API_KEY_SECRET = "あなたのAPI Key Secret"
ACCESS_TOKEN = "あなたのAccess Token"
ACCESS_TOKEN_SECRET = "あなたのAccess Token Secret"
twitter_oauth = OAuth1Session(API_KEY, API_KEY_SECRET, ACCESS_TOKEN, ACCESS_TOKEN_SECRET)
# APIのリソースURL
request_search_url = "https://api.twitter.com/1.1/search/tweets.json"
# 検索キーワードを指定
query = "~~~任意のキーワード~~~"
# パラメータの設定
params = {
"q": query,
"count": 100,
"locale": "ja",
"result_type": "recent"
}
# Twitter APIで検索を実行
res = twitter_oauth.get(request_search_url, params=params)
response = json.loads(res.text)
print(response)変数queryに「プログラミング」と指定した場合の実行結果を見てみましょう。
APIリクエストで指定できるパラメータ
引数paramsで指定できるパラメータ
| パラメータ | 意味 | 指定する値の例 |
|---|---|---|
| q (必須) | 検索クエリ(UTF-8で500文字以内) | |
| geocode | 指定した緯度/経度および半径内のユーザのツイートのみ検索 “経度 緯度 数値(miマイル)or(kmキロメートル)”のように指定 | “37.781157 -122.398720 1mi”など |
| lang | 指定した言語で投稿されたツイートのみを検索 | “eu”など |
| locale | 検索クエリqの言語を指定 | “ja”など |
| result_type | 検索結果の条件を「人気ツイート」「最新ツイート」「混合」から選択 | “mixed”, “recent”, “popular”のいずれか |
| count | 取得する検索結果のツイート数(最大100。デフォルト15) | 100, 30などのint型 |
| until | 指定日時以前のツイートのみを検索 (ツイート検索は現在より1週間前までしか取得されないことに注意) | “2022-08-30″など |
| since_id | 指定したIDより値の大きい(新しい)IDを持つツイートのみを検索 | 12345などのint型 |
| max_id | 指定したIDより値の小さい(古い)IDを持つツイートのみを検索 | 54321などのint型 |
| includes_entities | #やメンションなどのエンティティ情報を結果に含めるかどうか | “true”(含める), “false”(含めない)のいずれか |
検索結果データを項目ごとに整理
APIレスポンスはjsonフォーマットなので、すこしわかりづらいですよね。
項目ごとに整理されたデータフレームにまとめてみます。
# pandasライブラリをインポート
import pandas as pd
import json
from requests_oauthlib import OAuth1Session
API_KEY = "あなたのAPI Key"
API_KEY_SECRET = "あなたのAPI Key Secret"
ACCESS_TOKEN = "あなたのAccess Token"
ACCESS_TOKEN_SECRET = "あなたのAccess Token Secret"
twitter_oauth = OAuth1Session(API_KEY, API_KEY_SECRET, ACCESS_TOKEN, ACCESS_TOKEN_SECRET)
request_search_url = "https://api.twitter.com/1.1/search/tweets.json"
query = "~~~任意のキーワード~~~"
params = {
"q": query,
"count": 100,
"locale": "ja",
"result_type": "recent"
}
res = twitter_oauth.get(request_search_url, params=params)
response = json.loads(res.text)
##### APIレスポンスをpandasデータフレームにまとめる #####
# レスポンスデータはstatusesキーに格納されている
df = pd.DataFrame(response["statuses"])jupyter notebookなどで出力を確認すると、以下の通り
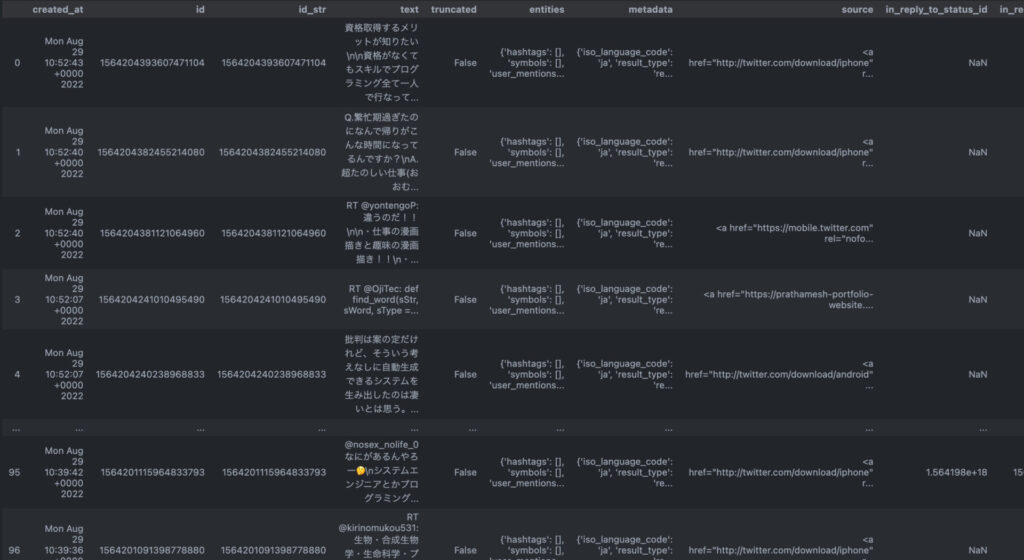
行と列ごとに内容が区切られたので、だいぶ出力がわかりやすくなりましたね。
指定した「プログラミング」というワードを含むツイートだけをタイムラインから検索・抽出できました。
データフレームの各列の内容は下表のようになっています。
| 列名 | 意味 |
|---|---|
| created_at | ツイート日時 |
| id | ツイートid |
| id_str | ツイートidの文字列型 |
| text | ツイートの本文 |
| truncated | ツイート本文が省略されているか |
| entities | ハッシュタグやユーザメンション情報 |
| source | ツイートのリンクURL |
| retweet_count | リツイートされた数 |
| favorite_count | いいねされた数 |
ツイート日時、ツイート本文、いいね数、リツイート数だけ抽出
データフレームの主要な項目だけに整理しましょう。
サンプルコード
import pandas as pd
df = pd.DataFrame(response["statuses"])
df_pickup = df[["created_at", "text", "favorite_count", "retweet_count"]]
df_pickup.sort_values(by="favorite_count", ascending=False)実行結果

まとめ
今回はPythonを使って、Twitter APIから特定ワードをタイムラインから検索する方法をご紹介しました。
Twitter運用・分析でも活用できるのでぜひ参考にして見てくださいね。
他にもTwitter APIの活用方法を紹介しているので、合わせてどうぞ。

