この記事ではpandasライブラリにおけるDataFrame(データフレーム)の使い方を具体的に解説します。
サンプルコードをコピペしながらサクサク処理を試せますので、 ぜひ活用してみてください。
ライブラリのインストール
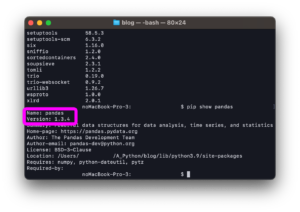
初めにpythonの実行環境にpandasライブラリをインストールしましょう。
ターミナル(mac)もしくはコマンドプロンプト(Windows)で以下を実行します。
pip install pandas最終行に「Successfully installed 〜〜〜」と表示されていれば、インストールは成功です。
pandasでデータフレームを作成
pandasのDateFrameは2次元配列、もしくは複数の1次元配列(リストなど)からデータテーブルを構成するオブジェクトです。
基本的なDataFrameの作成方法を見ていきましょう。
DataFrameの引数dataに配列を指定することでデータフレームを作成できます。
複数の1次元配列から作成
import pandas as pd
data1 = [0, 1, 2, 3]
data2 = [4, 5, 6, 7]
data3 = [8, 9, 10, 11]
# 複数の1次元配列からDataFrameを作成
df = pd.DataFrame(data=[data1, data2, data3])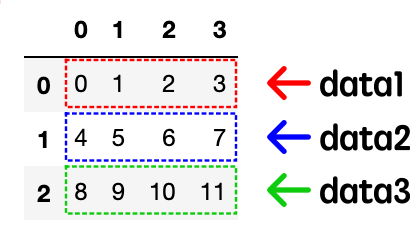
複数の1次元配列を並べて作成した場合のDataFrameの構造です。
1次元配列が順に各行の値となっていることがわかります。
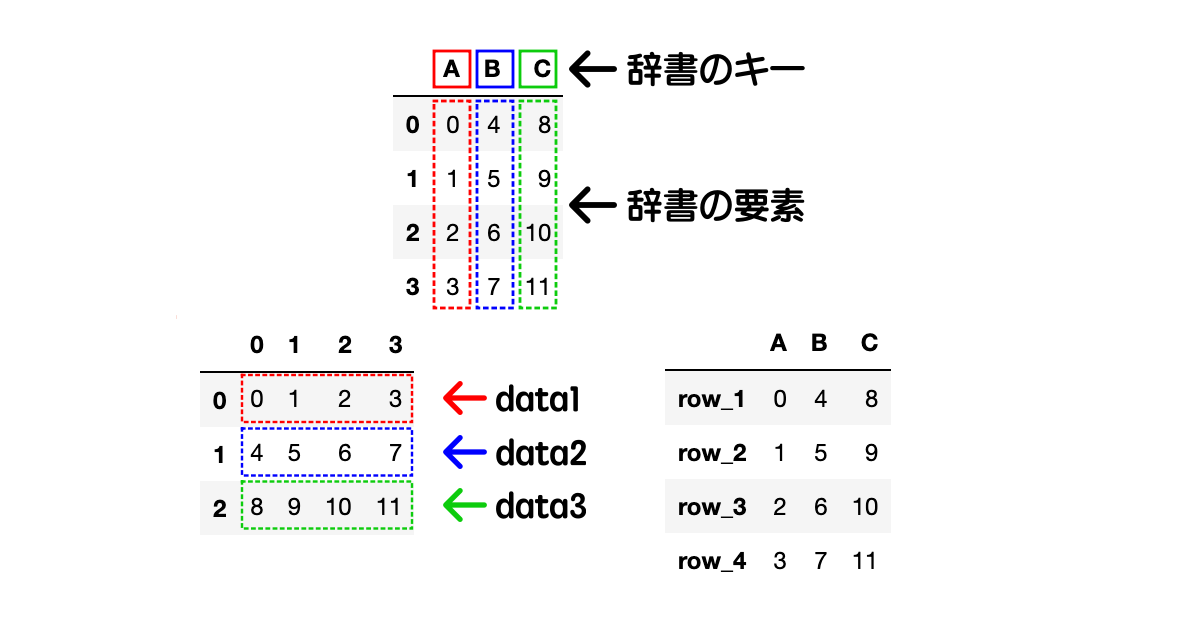
辞書型配列から作成
DataFrameを辞書型の配列から作ることもできます。
import pandas as pd
data1 = [0, 1, 2, 3]
data2 = [4, 5, 6, 7]
data3 = [8, 9, 10, 11]
# 辞書型からDataFrameを作成
df = pd.DataFrame(data={"A": data1, "B": data2, "C": data3})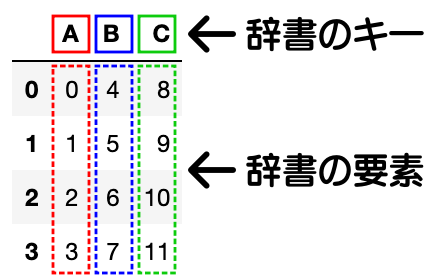
辞書型の配列からDataFrameを作成した場合、列名が辞書のキー、列の値が辞書の要素となる特徴があります。
numpyのndarray配列から作成
pythonのnumpyモジュールで構成される配列からもDataFrameを作成することができます。
import pandas as pd
import numpy as np
data1 = [0, 1, 2, 3]
data2 = [4, 5, 6, 7]
data3 = [8, 9, 10, 11]
# numpyのndarray配列からDataFrameを作成
df = pd.DataFrame(np.array([data1, data2, data3]))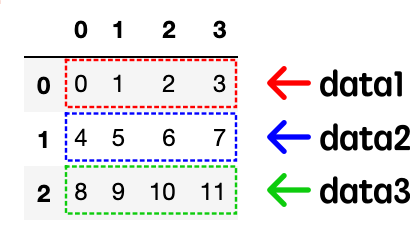
numpyのndarray配列からDataFrameを作成する場合、複数の1次元配列から作成するのとデータ構造は同じになります。
列名・行名を指定
作成したDataFrameの列名や行名を指定してみましょう。
列名(columns)を指定
DataFrameに列名を指定してみます。
引数columnsにDataFrameの列数と同じ要素数の配列を指定することで、列名を指定することができます。
import pandas as pd
data1 = [0, 1, 2, 3]
data2 = [4, 5, 6, 7]
data3 = [8, 9, 10, 11]
# 列名を指定
df = pd.DataFrame(data=[data1, data2, data3], columns=['col_1', 'col_2', 'col_3', 'col_4'])
行名(index)を指定
DataFrameの行名を指定してみます。
引数indexにDataFrameの行数と同じ要素数の配列を指定することで、行名を指定することができます。
import pandas as pd
data1 = [0, 1, 2, 3]
data2 = [4, 5, 6, 7]
data3 = [8, 9, 10, 11]
# 行名を指定
df = pd.DataFrame(data=[data1, data2, data3], index=['row_1', 'row_2', 'row_3'])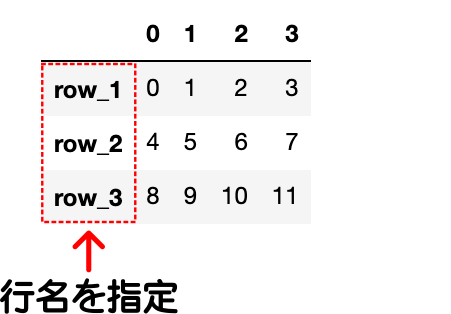
DataFrameの編集
列を追加
DataFrameに列を追加してみましょう。
df["列名"] = 配列によって、DataFrameに新たな列を追加することができます。
import pandas as pd
data1 = [0, 1, 2, 3]
data2 = [4, 5, 6, 7]
data3 = [8, 9, 10, 11]
# 基準のDataFrameを作成
df = pd.DataFrame(data={"A": data1, "B": data2, "C": data3})
# 列を追加
df["D"] = [12, 13, 14, 15]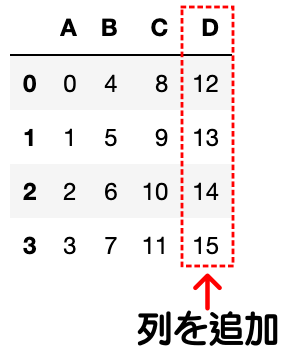
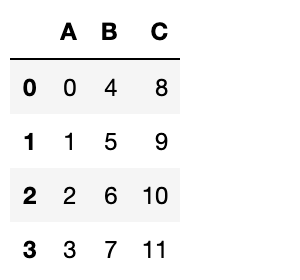
行を追加
DataFrameに行を追加してみましょう。
df.loc["行名"] = 配列で新たに行を追加することができます。
import pandas as pd
data1 = [0, 1, 2, 3]
data2 = [4, 5, 6, 7]
data3 = [8, 9, 10, 11]
# 基準のDataFrameを作成
df = pd.DataFrame({"A": data1, "B": data2, "C": data3}, index=['row_1', 'row_2', 'row_3', 'row_4'])
# 行を追加
df.loc["row_5"] = [100, 200, 300]
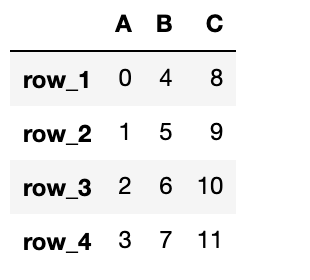
列の値を更新
DataFrameの列の値を更新してみましょう。
既存の列名に対して、df["列名"] = 新しい配列とすることで列の値を更新することができます。
値を更新すると古い値が書き変わってしまうため注意が必要です。
import pandas as pd
data1 = [0, 1, 2, 3]
data2 = [4, 5, 6, 7]
data3 = [8, 9, 10, 11]
# 基準のDataFrameを作成
df = pd.DataFrame({"A": data1, "B": data2, "C": data3}, index=['row_1', 'row_2', 'row_3', 'row_4'])
# A列の値を更新
df["A"] = [10, 100, 1000, 10000]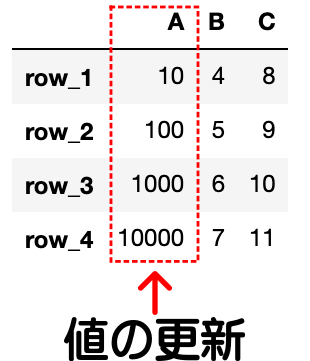
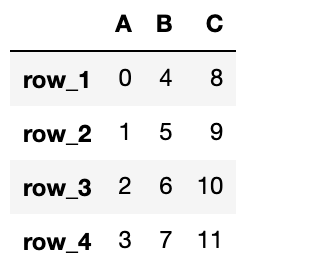
行の値を更新
DataFrameの行の値を更新してみましょう。
既存の行名に対して、df.loc["行名"] = 新しい配列とすることで列の値を更新することができます。
値を更新すると古い値が書き変わってしまうため注意が必要です。
import pandas as pd
data1 = [0, 1, 2, 3]
data2 = [4, 5, 6, 7]
data3 = [8, 9, 10, 11]
# 基準のDataFrameを作成
df = pd.DataFrame({"A": data1, "B": data2, "C": data3}, index=['row_1', 'row_2', 'row_3', 'row_4'])
# 行row_3の値を更新
df.loc["row_3"] = [10, 100, 1000]
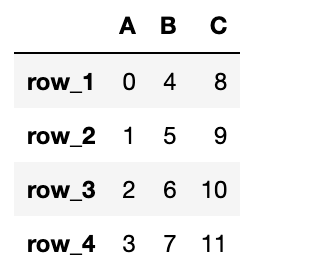
列の削除(drop)
既存のDataFrameから列を削除してみましょう。
列を削除するにはdf.drop("列名", axis=1, inplace=True)を使用します。
inplace=Trueと指定することで削除前のDataFrameを上書きし、置き換えます。
import pandas as pd
data1 = [0, 1, 2, 3]
data2 = [4, 5, 6, 7]
data3 = [8, 9, 10, 11]
# 基準のDataFrameを作成
df = pd.DataFrame({"A": data1, "B": data2, "C": data3}, index=['row_1', 'row_2', 'row_3', 'row_4'])
# C列を削除(axis=1で列を削除)
df.drop("C", axis=1, inplace=True)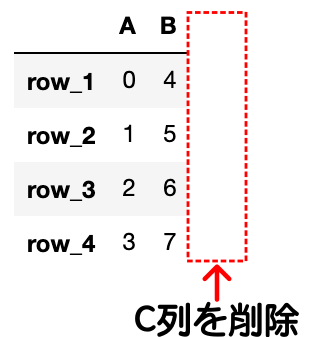
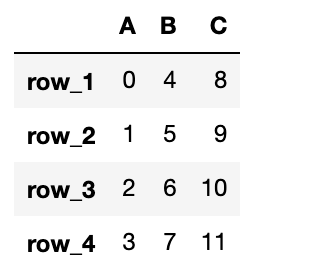
行の削除(drop)
既存のDataFrameから行を削除してみましょう。
行を削除するにはdf.drop("行名", axis=0, inplace=True)を使用します。
inplace=Trueと指定することで削除前のDataFrameを上書きし、置き換えます。
import pandas as pd
data1 = [0, 1, 2, 3]
data2 = [4, 5, 6, 7]
data3 = [8, 9, 10, 11]
# 基準のDataFrameを作成
df = pd.DataFrame({"A": data1, "B": data2, "C": data3}, index=['row_1', 'row_2', 'row_3', 'row_4'])
# 行row_4を削除(axis=0で行を削除)
df.drop("row_4", axis=0, inplace=True)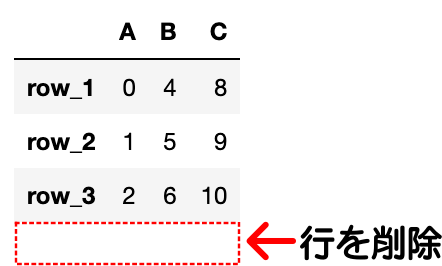
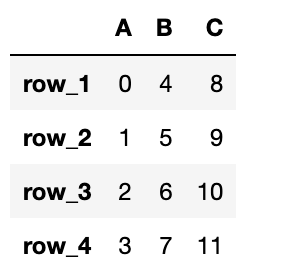
DataFrameから特定の値を取得
特定の列の値を取得
既存のDataFrameから特定の列の値を取得してみましょう。
特定の列の値を取得するにはdf["列名"].valuesを使用します。
import pandas as pd
data1 = [0, 1, 2, 3]
data2 = [4, 5, 6, 7]
data3 = [8, 9, 10, 11]
# 基準のDataFrameを作成
df = pd.DataFrame({"A": data1, "B": data2, "C": data3}, index=['row_1', 'row_2', 'row_3', 'row_4'])上のようなDataFrameのB列の値を取得してみましょう。
# B列の値を取得
print(df["B"].values)# 出力結果
[4 5 6 7]複数の列をまとめて取得
複数の列をまとめて取得することもできます。
複数列を取得するにはdf[列名の配列]を使用します。
import pandas as pd
data1 = [0, 1, 2, 3]
data2 = [4, 5, 6, 7]
data3 = [8, 9, 10, 11]
# 基準のDataFrameを作成
df = pd.DataFrame({"A": data1, "B": data2, "C": data3}, index=['row_1', 'row_2', 'row_3', 'row_4'])
# B, C列を取得
df_BC = df[["B", "C"]]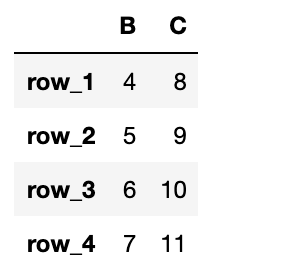
B列とC列のDataFrameを取得されていることがわかります。
特定の行の値を取得
既存のDataFrameから特定の列の値を取得してみましょう。
特定の列の値を取得するにはdf.loc["行名"].valuesを使用します。
import pandas as pd
data1 = [0, 1, 2, 3]
data2 = [4, 5, 6, 7]
data3 = [8, 9, 10, 11]
# 基準のDataFrameを作成
df = pd.DataFrame({"A": data1, "B": data2, "C": data3}, index=['row_1', 'row_2', 'row_3', 'row_4'])上のDataFrameから行row_2の値を取得してみましょう。
# 列row_2の値を取得
data_r2 = df.loc["row_2"]
print(data_r2.values)# 出力結果
[1 5 9]複数の行をまとめて取得
複数の行をまとめて取得することもできます。
複数行を取得するにはdf.loc[行名の配列]を使用します。
import pandas as pd
data1 = [0, 1, 2, 3]
data2 = [4, 5, 6, 7]
data3 = [8, 9, 10, 11]
# 基準のDataFrameを作成
df = pd.DataFrame({"A": data1, "B": data2, "C": data3}, index=['row_1', 'row_2', 'row_3', 'row_4'])
# 行row_2, row_3を取得
df_r23 = df.loc[["row_2", "row_3"]]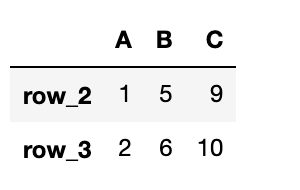
行row_2と行row_3のDataFrameが取得されていることがわかります。
まとめ
今回はpandasライブラリでDataFrameを扱う方法を具体的に紹介しました。
データ整理やデータ分析の際にpandasのDataFrameオブジェクトはとても便利ですので、ぜひ活用してみてください。