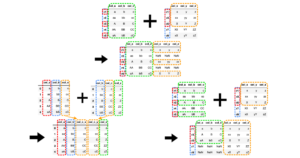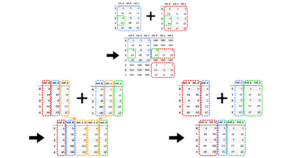
この記事ではpandasライブラリにおけるDataFrameを結合(join)する方法を具体的に解説します。
サンプルコードをコピペしながらサクサク処理を試せますので、 ぜひ活用してみてください。
pandasのDataFrame結合
pandasにおいてDataFrameを結合する方法は大きく3種類存在します。
インデックスをキーとして結合
pd.DataFrame.join()
この記事ではpd.DataFrame.join()での結合方法を具体的に紹介します。
pd.DataFrame.join()の使い方
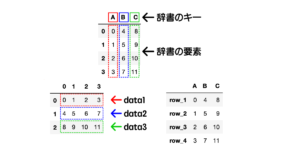
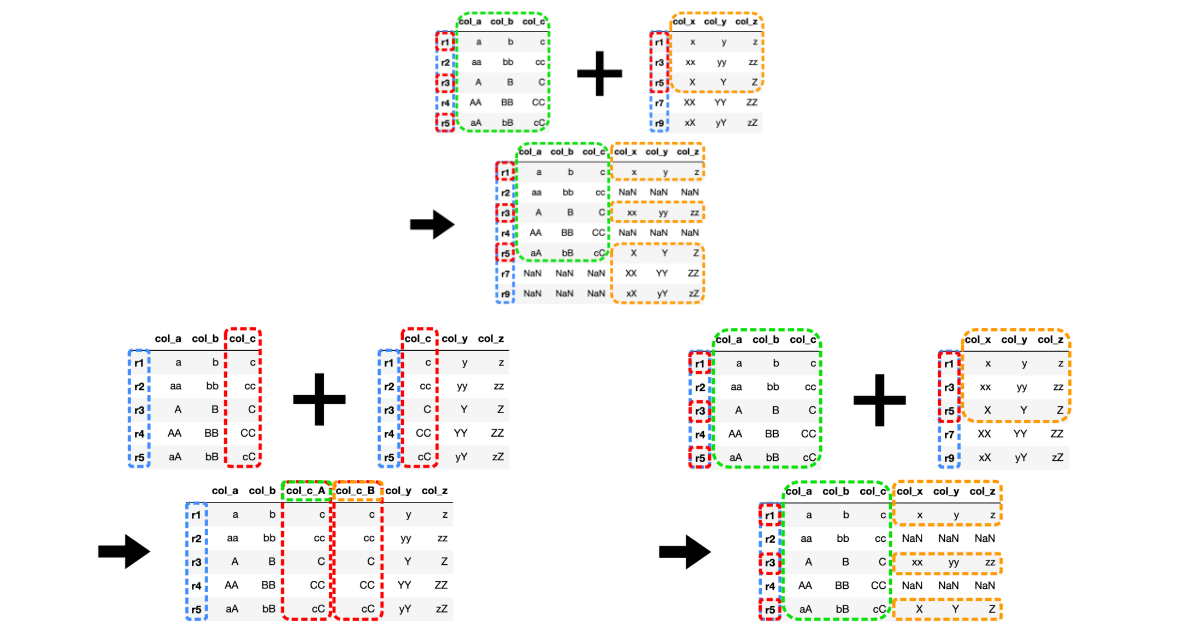
pd.DataFrame.join()ではDataFrameのインデックス(行名)をキーとして横方向に結合します。
import pandas as pd
# 2つのDataFrameを作成(共通のインデックス)
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]}, index=["r1", "r2", "r3", "r4", "r5"])
df2 = pd.DataFrame({"col_x": ["x", "xx", "X", "XX", "xX"], "col_y": ["y", "yy", "Y", "YY", "yY"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]}, index=["r1", "r2", "r3", "r4", "r5"])
# df1とdf2を結合
df3 = df1.join(df2)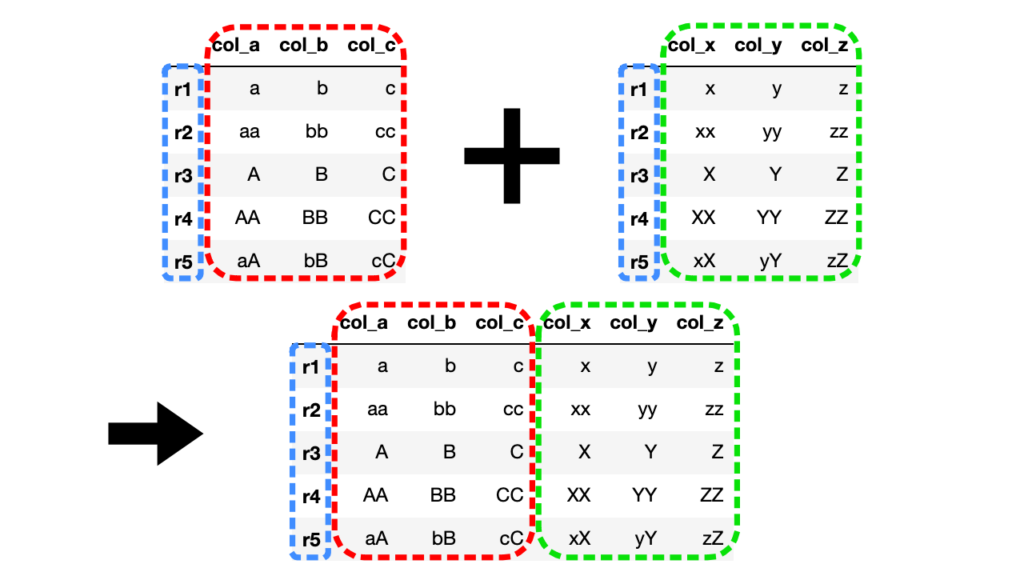
インデックス(行名)を基準に横方向からDataFrameが結合されています。
共通の列名を持つ場合の結合
結合するDataFrameで共通の列名を持っている場合、結合の左側と右側の共通列にサフィックスを指定する必要があります。
引数lsuffix, rsuffixをそれぞれ指定しないとエラーが出ます。
import pandas as pd
# 2つのDataFrameを作成(共通のインデックス & 共通の列col_c)
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]}, index=["r1", "r2", "r3", "r4", "r5"])
df2 = pd.DataFrame({"col_c": ["c", "cc", "C", "CC", "cC"], "col_y": ["y", "yy", "Y", "YY", "yY"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]}, index=["r1", "r2", "r3", "r4", "r5"])
# 左右のサフィックスを指定する必要がある
df3 = df1.join(df2, lsuffix="_A", rsuffix="_B")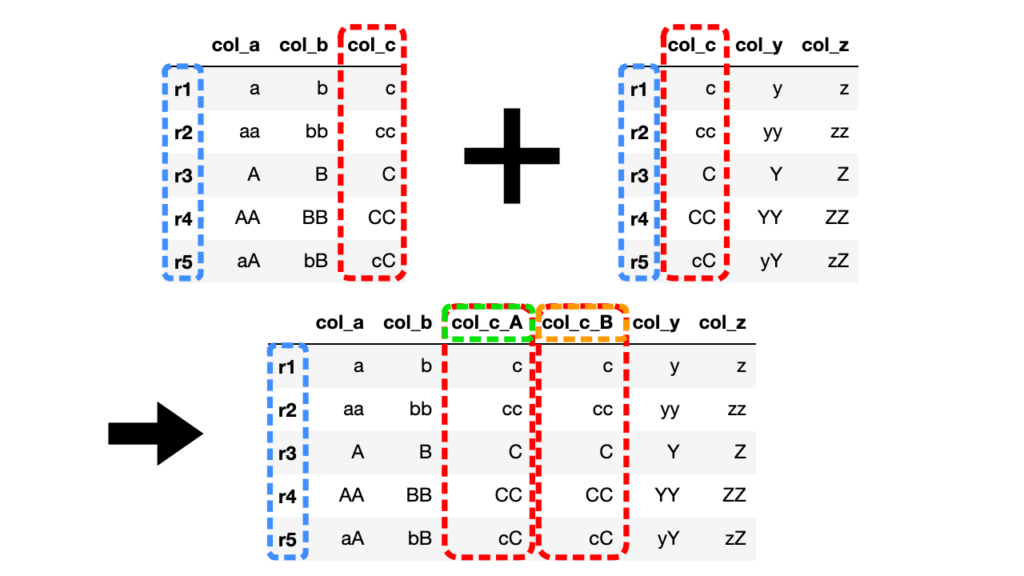
共通列col_cが左右それぞれ引数で指定したcol_c_A, col_c_Bとなって新たに生成されていることがわかります。
結合方法
pd.DataFrame.join()での結合方法は左外部結合がデフォルトになっています。
左外部結合(デフォルト)
右外部結合
完全外部結合
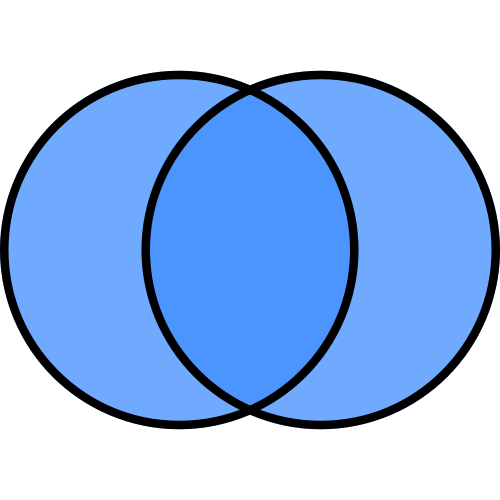
内部結合
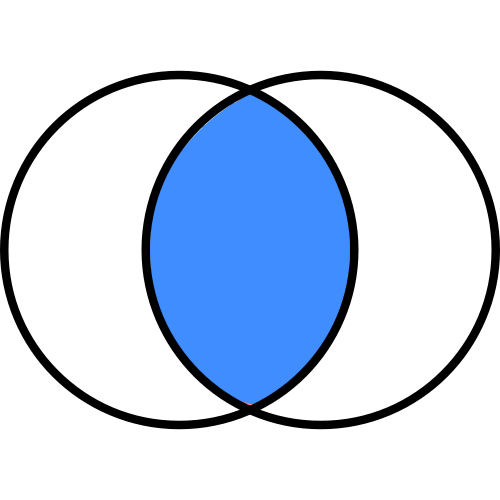
左外部結合(left)
左外部結合では左側DataFrameに右側DataFrameを足す形になります。
import pandas as pd
# 2つのDataFrameを作成
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]}, index=["r1", "r2", "r3", "r4", "r5"])
df2 = pd.DataFrame({"col_x": ["x", "xx", "X", "XX", "xX"], "col_y": ["y", "yy", "Y", "YY", "yY"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]}, index=["r1", "r3", "r5", "r7", "r9"])
# 左外部結合(how="left")
df3 = df1.join(df2, how="left")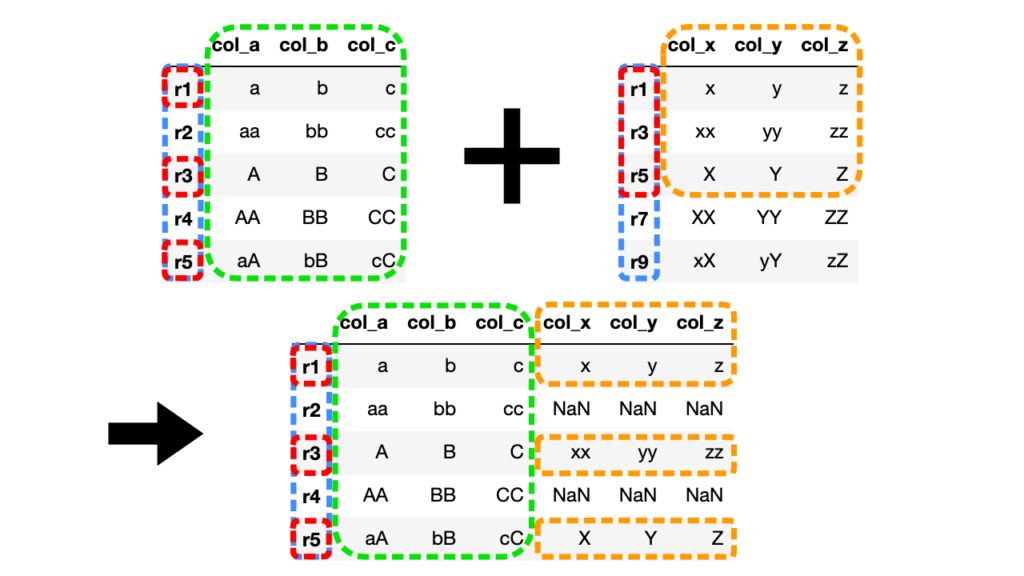
左側のDataFrameを基準に共通する値を持つ行だけが結合されます。
その他の値はNaN(Not a Number)で埋められます。
右外部結合(right)
右外部結合では右側DataFrameに左側DataFrameを足す形になります。
import pandas as pd
# 2つのDataFrameを作成
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]}, index=["r1", "r2", "r3", "r4", "r5"])
df2 = pd.DataFrame({"col_x": ["x", "xx", "X", "XX", "xX"], "col_y": ["y", "yy", "Y", "YY", "yY"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]}, index=["r1", "r3", "r5", "r7", "r9"])
# 右外部結合(how="right")
df3 = df1.join(df2, how="right")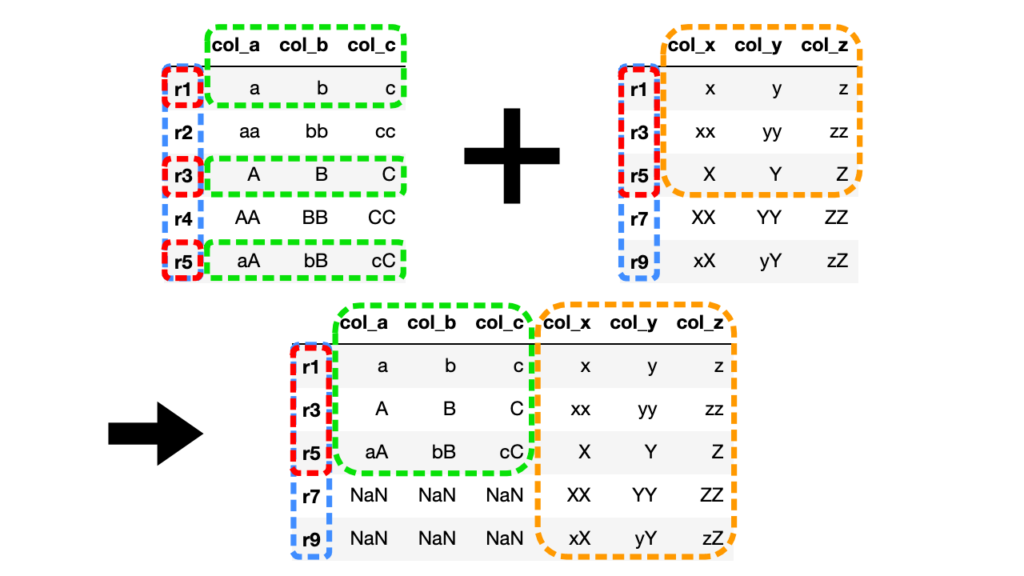
右側のDataFrameを基準に共通する値を持つ行だけが結合されます。
その他の値はNaN(Not a Number)で埋められます。
完全外部結合(outer)
完全外部結合では両方のDataFrameをそのまま足す形になります。
import pandas as pd
# 2つのDataFrameを作成
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]}, index=["r1", "r2", "r3", "r4", "r5"])
df2 = pd.DataFrame({"col_x": ["x", "xx", "X", "XX", "xX"], "col_y": ["y", "yy", "Y", "YY", "yY"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]}, index=["r1", "r3", "r5", "r7", "r9"])
# 完全外部結合(how="outer")
df3 = df1.join(df2, how="outer")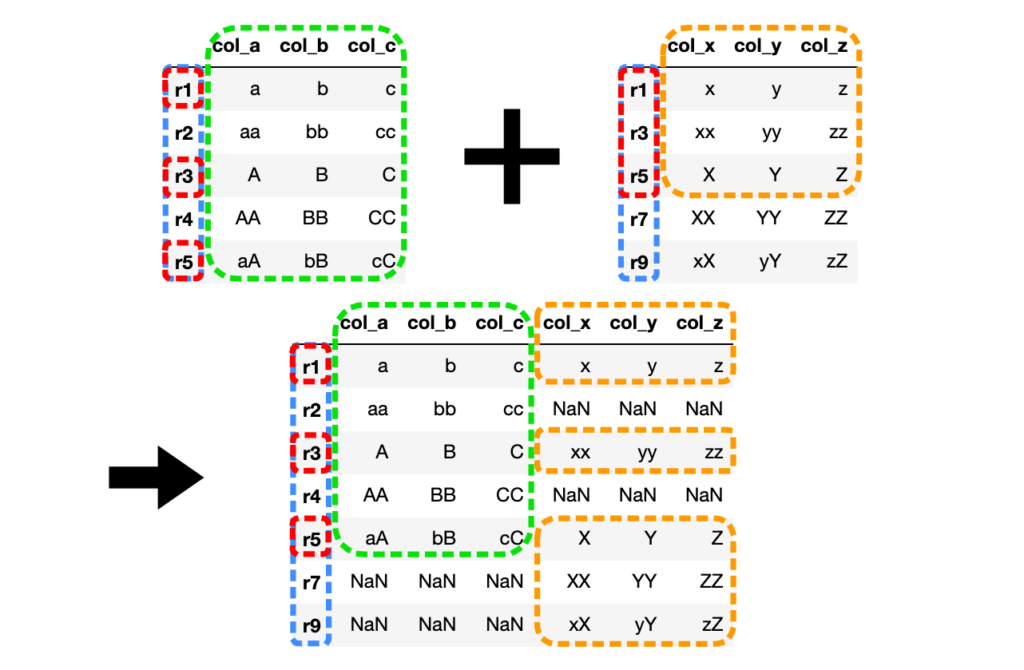
両方のDataFrameをにインデックス(行名)で共通の値を持つ行を結合し、
共通の値を持たない行の値はNaN(Not a Number)で埋められます。
内部結合(inner)
内部結合では左右のDataFrameの共通部分だけを残すように結合します。
import pandas as pd
# 2つのDataFrameを作成
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]}, index=["r1", "r2", "r3", "r4", "r5"])
df2 = pd.DataFrame({"col_x": ["x", "xx", "X", "XX", "xX"], "col_y": ["y", "yy", "Y", "YY", "yY"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]}, index=["r1", "r3", "r5", "r7", "r9"])
# 内部結合(how="inner")
df3 = df1.join(df2, how="inner")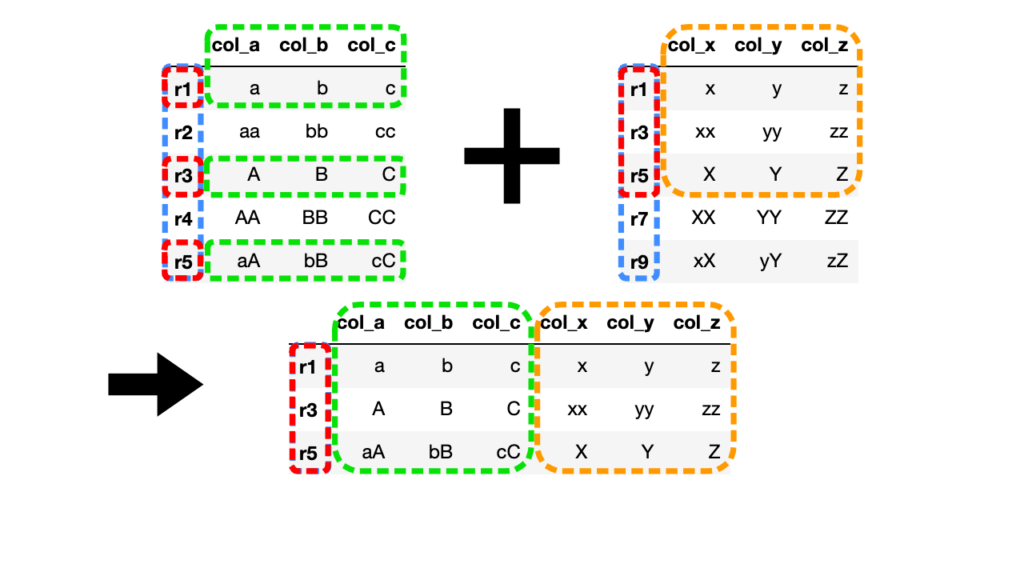
両方のDataFrameインデックスの共通する行のみを結合します。
左側DataFrameのキーを列名で指定(on)
左側DataFrameの結合キーをインデックスでなく、別の列名で指定できる。(左側DataFrameからしか選べない)
import pandas as pd
# 2つのDataFrameを作成
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_k": ["k", "kk", "K", "KK", "kK"]}, index=["r1", "r2", "r3", "r4", "r5"])
df2 = pd.DataFrame({"col_x": ["x", "xx", "X", "XX", "xX"], "col_y": ["y", "yy", "Y", "YY", "yY"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]}, index=["k'", "k'k'", "K", "KK", "k'K"])
# 左側DataFrameの結合キーを指定(on="col_k")
df3 = df1.join(df2, on="col_k")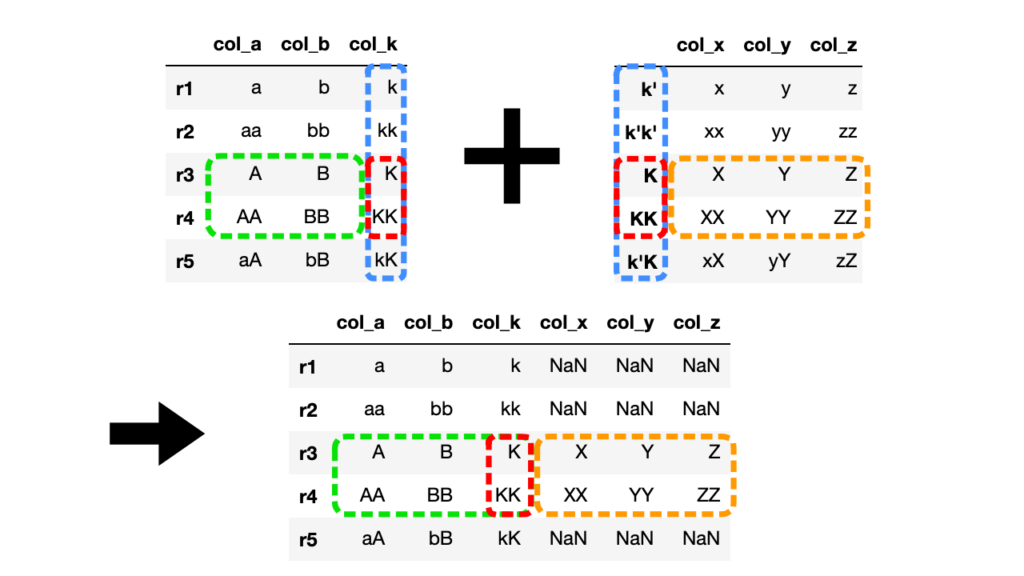
左側DataFrameの列名を指定して、右側DataFrameインデックスとの共通部分を結合します。
並び順をソート(sort)
結合後のDataFrameインデックスを昇順にソートすることができます。
import pandas as pd
# 2つのDataFrameを作成
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]}, index=["r3", "r5", "r4", "r1", "r2"])
df2 = pd.DataFrame({"col_x": ["x", "xx", "X", "XX", "xX"], "col_y": ["y", "yy", "Y", "YY", "yY"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]}, index=["r2", "r1", "r3", "r5", "r4"])
# 結合後のDataFrameインデックスを昇順にソート
df3 = df1.join(df2, sort=True)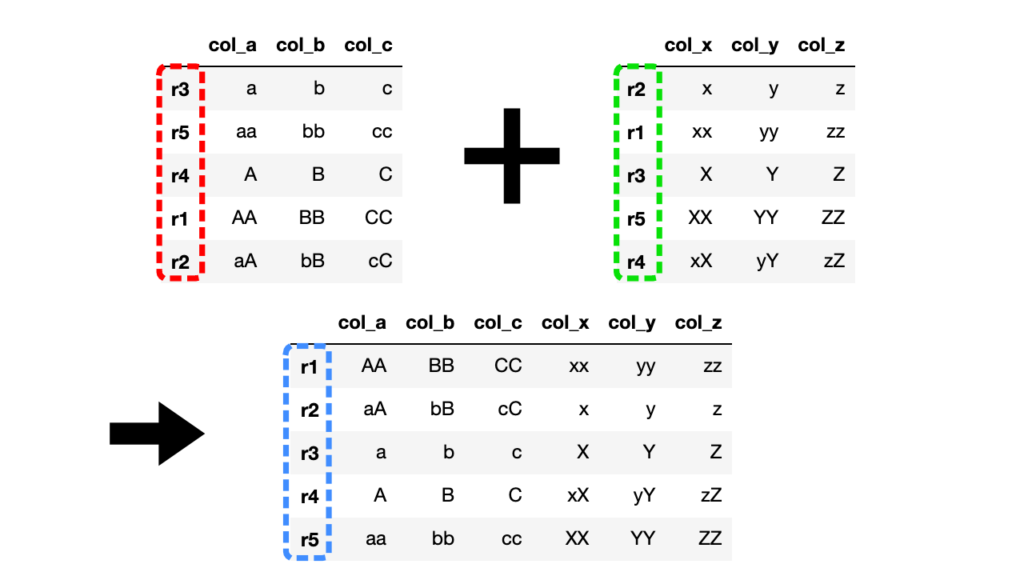
左右のDataFrameインデックスの並びがバラバラであっても、結合後にソートできます。
まとめ
今回はpandasのDataFrameを結合(join)する方法を具体的に解説しました。
pandasのDataFrame結合はとても複雑ですので、何度も使って慣れていけば良いと思います。