この記事では、pandasのDataFrameをcsvファイルに書き込む方法を具体的に紹介します。
サンプルコードを見ながら、サクサク処理を試せますので、ぜひ活用してみて下さい。
ライブラリのインストール
はじめにpandasライブラリをインストールしましょう。
ターミナル(mac)もしくはコマンドプロンプト(Windows)で以下を実行します。
pip install pandas最終行に「Successfully installed 〜〜〜」と表示されていればインストールは成功です。
pandasでcsvファイルに書き込み(to_csv())
pandasライブラリには、作成したDataFrameをcsvに書き込むto_csv()メソッド用意されています。
import pandas as pd
# DataFrameを作成
df = pd.DataFrame({"A": [0, 1, 2], "B": [3, 4, 5], "C": [6, 7, 8]}, index=["row1", "row2", "row3"])
# csvに書き込み・保存
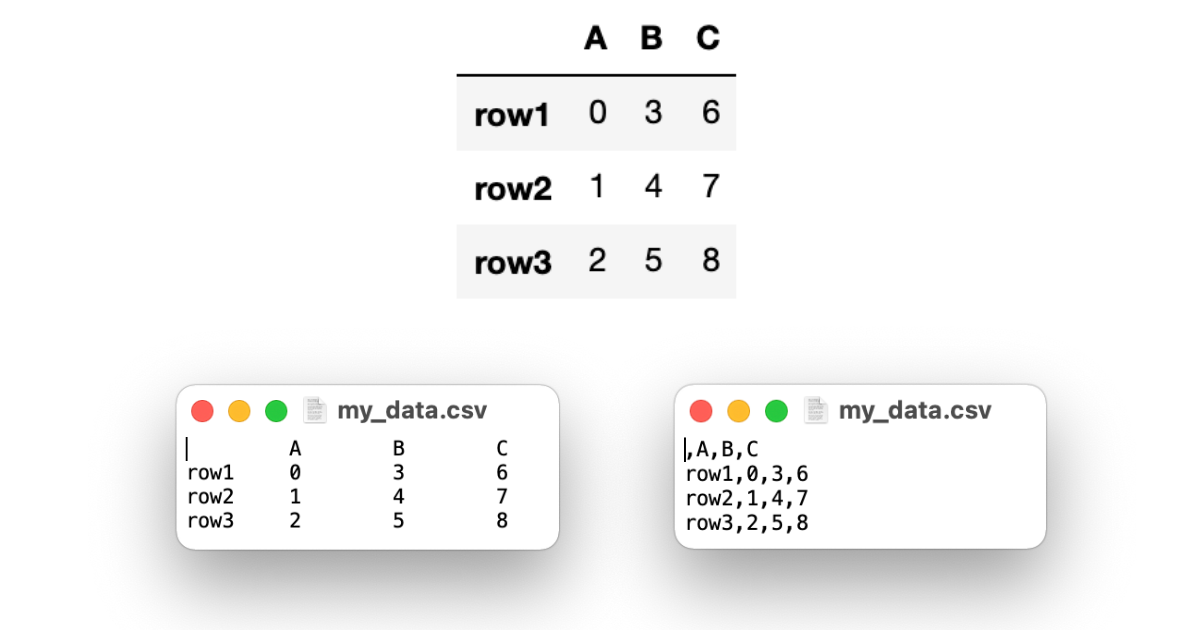
df.to_csv("my_data.csv")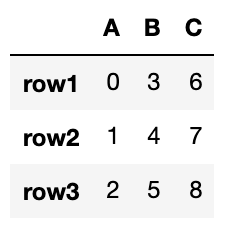

pandasで作成したDataFrameがcsvファイルに書き込み、保存されていることがわかります。
ここからは、csv書き込みの細かい設定を確認していきましょう。
特定の列だけを書き込み(columns)
作成したDataFrameのうち、指定した列だけをcsvファイルに書き込むことができます。
引数columnsに書き込みたい列名のリストを指定します。
import pandas as pd
# DataFrameを作成
df = pd.DataFrame({"A": [0, 1, 2], "B": [3, 4, 5], "C": [6, 7, 8]}, index=["row1", "row2", "row3"])
# B, C列だけをcsvに書き込み
df.to_csv("my_data.csv", columns=["B", "C"])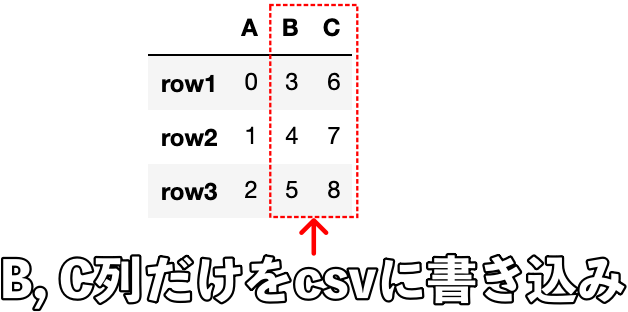

作成したDataFrame内の指定した列だけがcsvファイルに書き込まれていることがわかります。
ヘッダーの有無(header)
csvファイルにDataFrameを書き込む際、DataFrameの列名(ヘッダー)を書き込むかどうかを指定できます。
引数headerにTrue, Falseのどちらかを選択してヘッダーの有無を指定します。(デフォルトはTrue)
import pandas as pd
# DataFrameを作成
df = pd.DataFrame({"A": [0, 1, 2], "B": [3, 4, 5], "C": [6, 7, 8]}, index=["row1", "row2", "row3"])
# ヘッダーなしでcsvに書き込み(header=False)
df.to_csv("my_data.csv", header=False)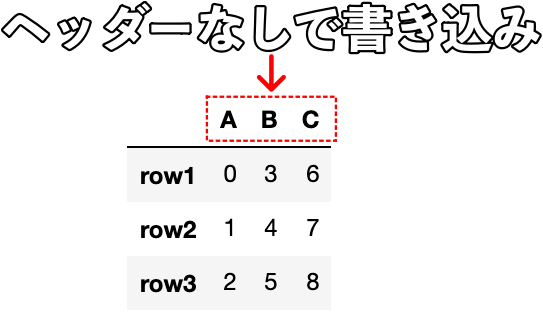
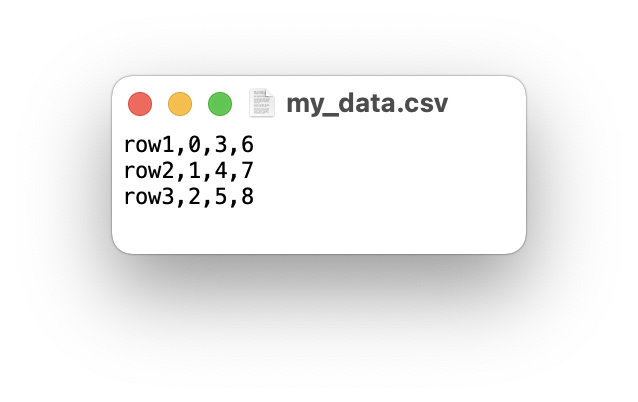
作成したDataFrameのヘッダー(列名)がcsvファイルに含まれていないことがわかります。
インデックスの有無(index)
csvファイルにDataFrameを書き込む際、DataFrameのインデックス(行名)を書き込むかどうかを指定できます。
引数indexにTrue, Falseのどちらかを選択してインデックス(行名)の有無を指定します。
(デフォルトはTrue)
import pandas as pd
# DataFrameを作成
df = pd.DataFrame({"A": [0, 1, 2], "B": [3, 4, 5], "C": [6, 7, 8]}, index=["row1", "row2", "row3"])
# インデックスなしでcsvに書き込み(index=False)
df.to_csv("my_data.csv", index=False)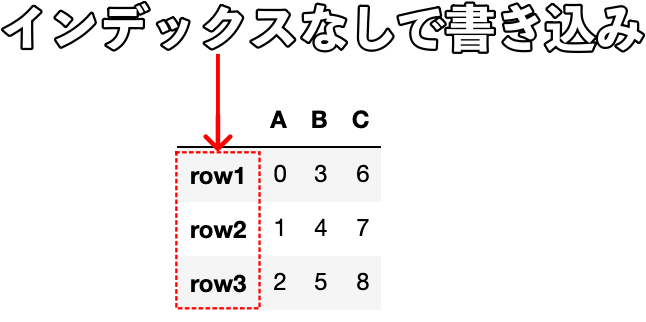

作成したDataFrameのインデックス(行名)がcsvファイルに含まれていないことがわかります。
区切り文字の指定(sep)
csvファイルへの書き込みの区切り文字を指定できます。
引数sepにtab区切り文字である"\t"を指定してみます。なお、デフォルトはカンマ区切り文字","です。
import pandas as pd
# DataFrameを作成
df = pd.DataFrame({"A": [0, 1, 2], "B": [3, 4, 5], "C": [6, 7, 8]}, index=["row1", "row2", "row3"])
# tab区切り文字で書き込み(tsv形式)
df.to_csv("my_data.csv", sep="\t")

区切り文字がカンマ","からタブ"\t"に変わっていることがわかります。
文字コードの指定(encoding)
csvファイルに書き込み際の文字コードを指定することができます。
引数encodingに任意の文字コードを指定します。デフォルトは"utf-8"です。
import pandas as pd
# DataFrameを作成
df = pd.DataFrame({"A": [0, 1, 2], "B": [3, 4, 5], "C": [6, 7, 8]}, index=["row1", "row2", "row3"])
# 文字コードを指定してcsv書き込み
df.to_csv("my_data.csv", encoding="shift_jis")書き込みモードを指定(mode)
csvファイルに書き込む際の書き込みモードを指定できます。
引数modeに下記一覧から書き込みモードを指定します。
| 引数modeの値 | 意味 |
|---|---|
"w" | 新規作成、上書き(デフォルト) |
"a" | 追記 |
"x" | ファイルが存在する場合のみ追記 |
import pandas as pd
# DataFrameを作成
df = pd.DataFrame({"A": [0, 1, 2], "B": [3, 4, 5], "C": [6, 7, 8]}, index=["row1", "row2", "row3"])
# 書き込みモードを指定してcsv書き込み
df.to_csv("my_data.csv", mode="a")
書き込み先のファイルを上書きするか、追記するかで使い分けましょう。
まとめ
今回はpandasのDataFrameをcsvファイルに書き込む方法を具体的に紹介しました。
データ整理・分析の結果をデータファイルとして保存しておけますので、ぜひ活用してみてください。