
本ページには PR が含まれます。
この記事ではseleniumライブラリを使ってWeb上のデータをスクレイピングする方法を具体的に解説します。
サンプルコードをコピペしながら、サクサク処理を試せますのでぜひ活用してみてください。
体系的にWebスクレピング技術を学びたい方へ
Pythonの実践的なWebスクレイピング技術について学びたいという方に向けてUdemy学習コースを公開しています。
\10/27(金)までの 90%OFFクーポンで Webスクレイピングを学べる!!/
30日間返金保証!
すぐにでもスクレイピング技術を活かせるようになりますよ!
pythonのスクレイピングライブラリ
pythonには代表的なWebスクレイピング用のライブラリが2つあります。
Selenium
- ChromeDriverと組み合わせて使用
- ライブラリひとつでデータ取得、抽出が可能
この記事ではseleniumライブラリにフォーカスして、Webスクレイピングの実践方法を紹介します。
seleniumライブラリでできること
seleniumライブラリを使用するWebスクレイピングでは、BeautifulSoupにはできない処理を実装できます。
seleniumライブラリの一番の魅力はブラウザの自動操作です。
- Webサイト入力欄への自動入力・送信
- ログイン機能のあるWebサイトへの自動ログイン
- Webサイトのボタンを自動クリック
など、人が行うブラウザ操作をプログラムに処理させられます。
それでは、seleniumライブラリを使ったWebスクレイピングの実装方法を見ていきましょう!!
ChromeDriverのインストール
seleniumライブラリを使ってWebスクレイピングを実装するには、
ChromeDriverというブラウザを自動操作するソフトウェアのインストールが必要です。
手軽に無料でダウンロードできますのでインストール方法を確認しましょう。
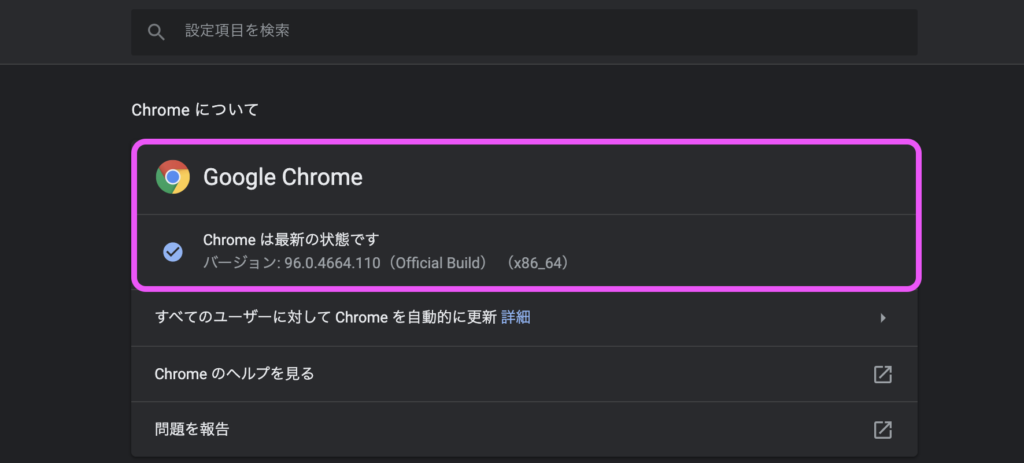
Google Chromeのバージョン確認
ChromeDriverをダウンロードする前にご自身の使用するGoogle Chromeのバージョンを確認します。
ChromeDriverとGoogle Chromeのバージョンが一致していないとエラーが発生する可能性があります。
Google Chromeを起動して、右上のメニューマークをクリックします。
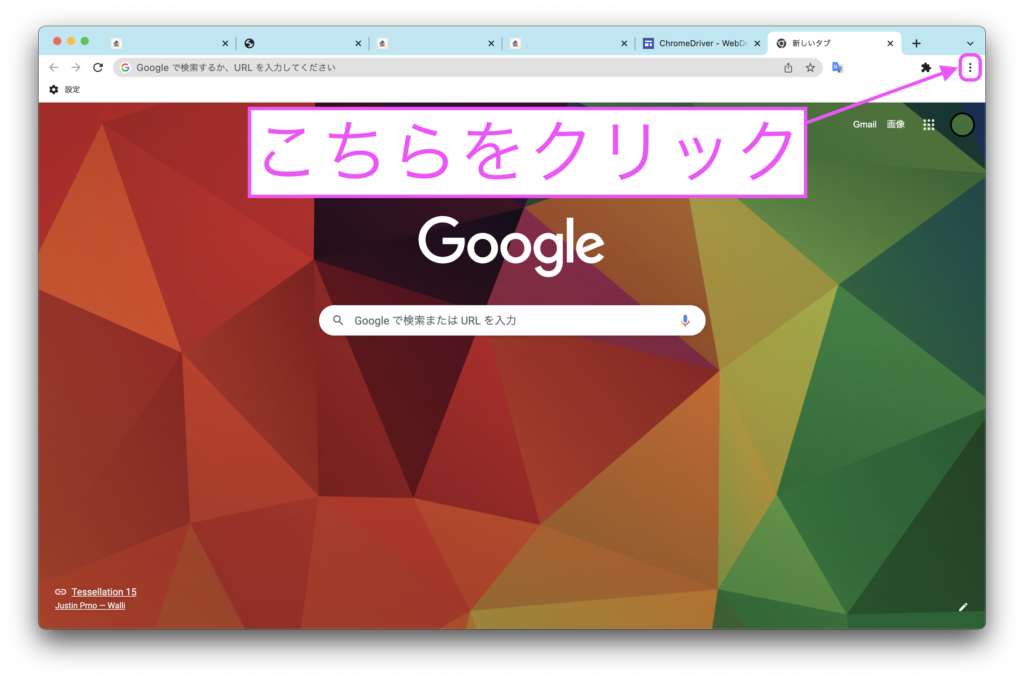
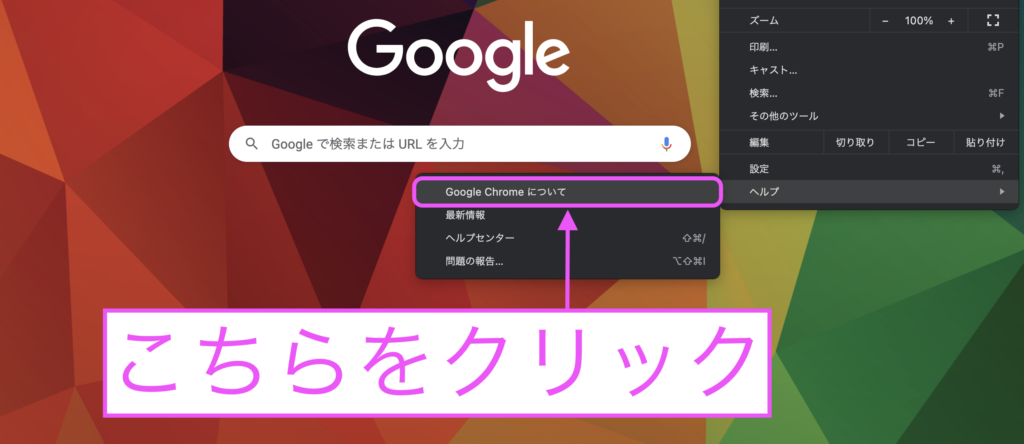
「ヘルプ」から「Google Chromeについて」をクリックするとバージョンを確認できます。
ダウンロードサイトからインストール
Google Chromeのバージョンが確認できたら、早速ChromeDriverをインストールしましょう。
こちらのサイトから無料でダウンロードできます。
先ほど確認したバージョンと一致するものを選択し、PCのOSに合ったダウンロードリンクをクリックします。
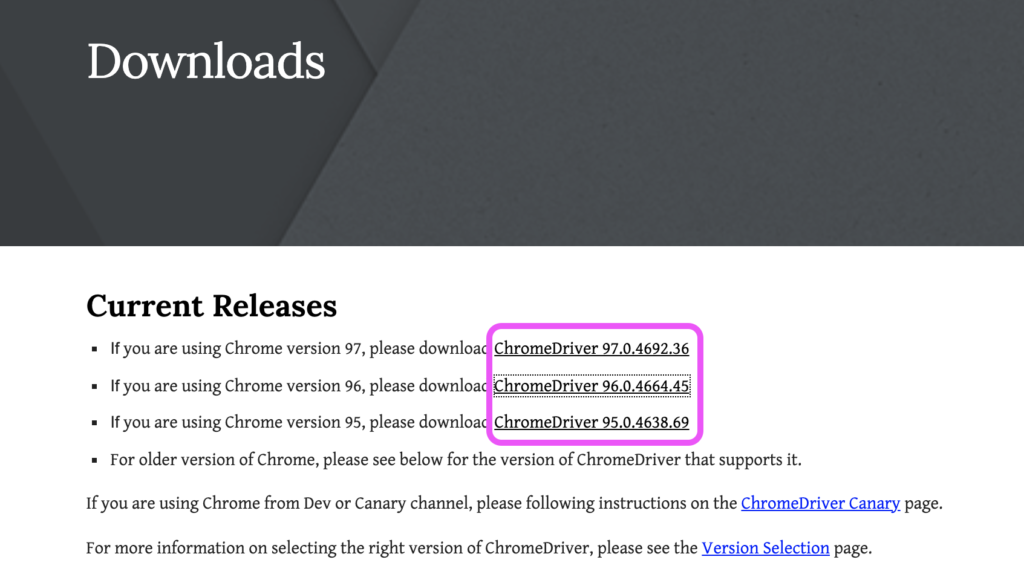
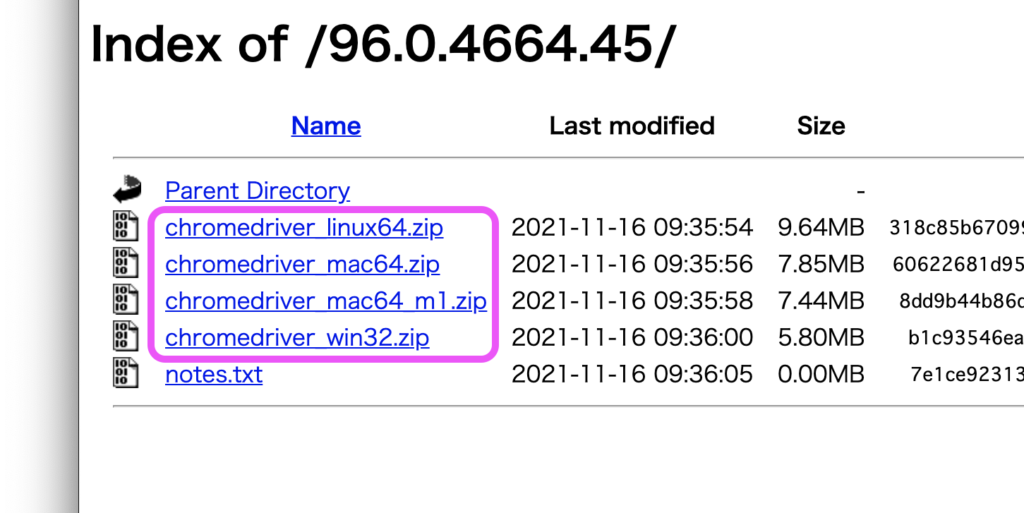
ダウンロードしたzipファイルをダブルクリックして解凍します。
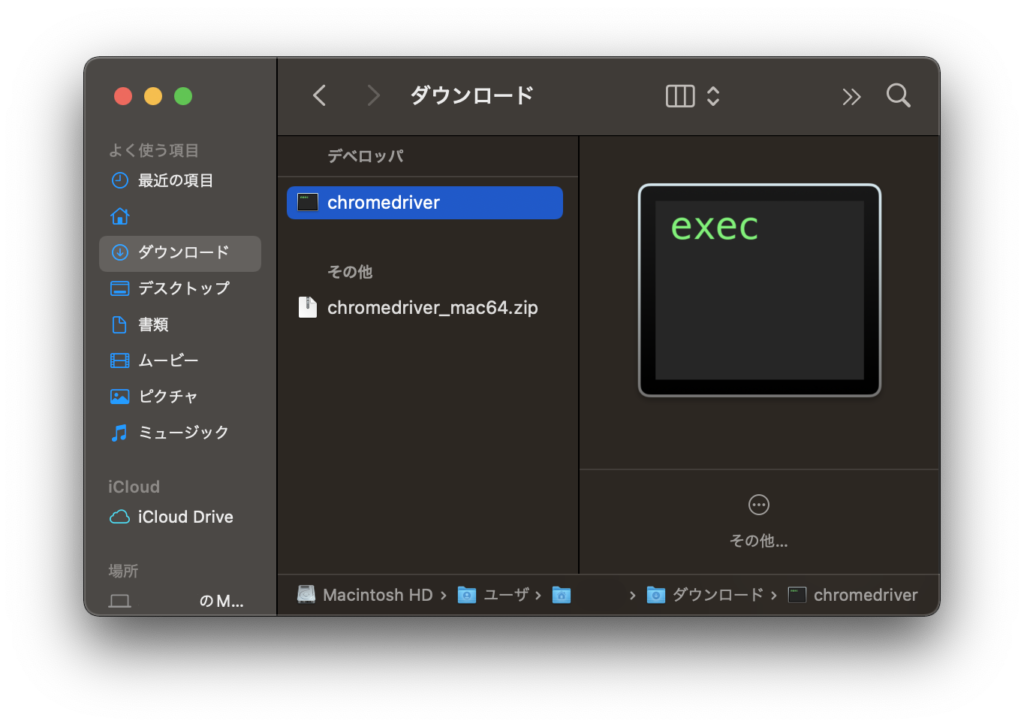
ライブラリのインストール
pythonの実行環境にseleniumライブラリをインストールします。
ターミナル(mac)もしくはコマンドプロンプト(Windows)で下記を実行します。
pip install selenium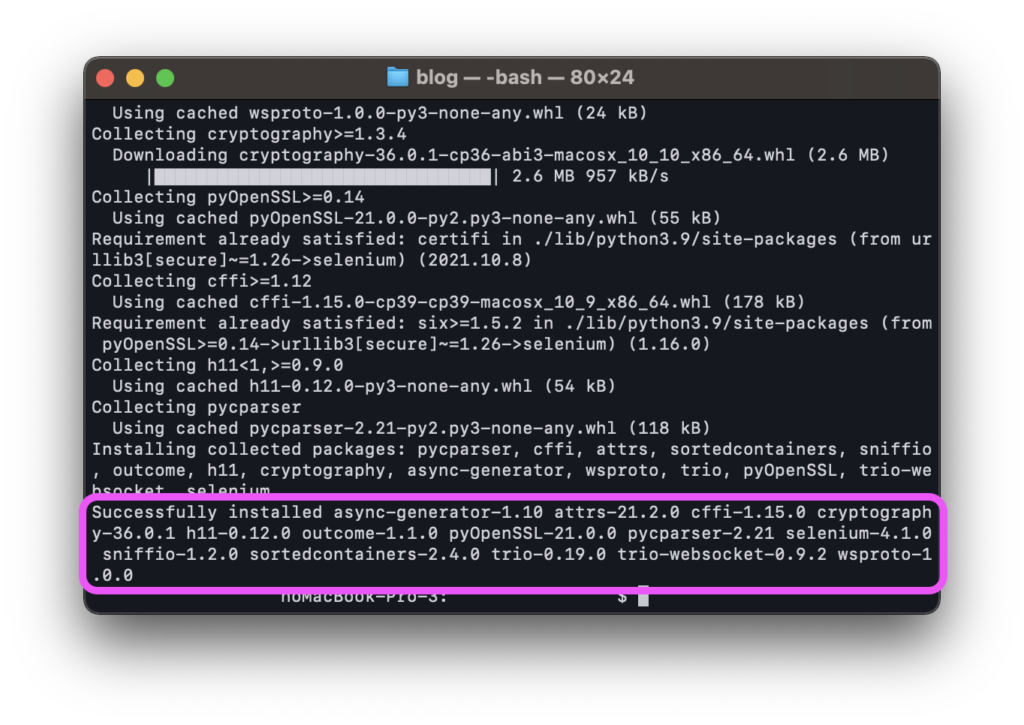
最終項に「Successfully installed 〜〜〜」と表示されていればインストールは成功です。
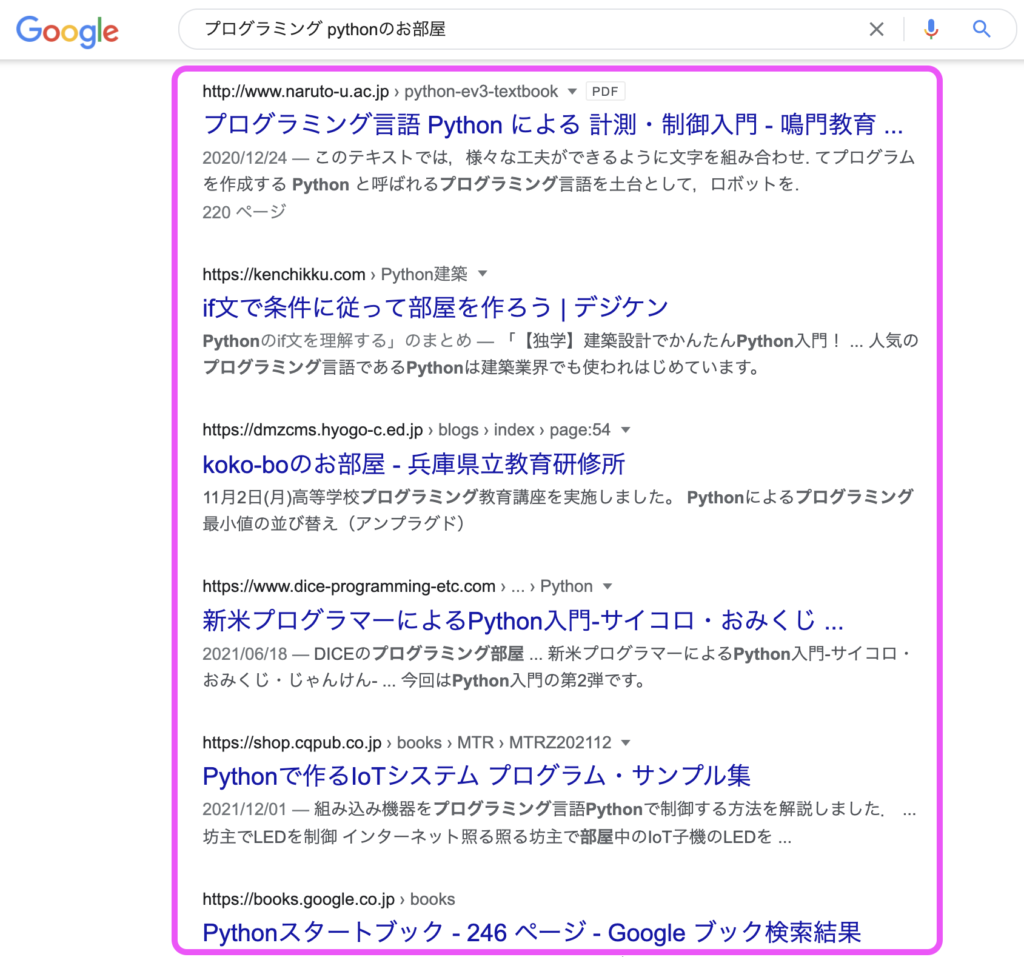
(実装例) Google検索結果から記事一覧を抽出
この記事ではseleniumライブラリを使ったWebスクレイピングの実装例として、
「Google検索結果から上位10記事のタイトルとURLの抽出」を実装していきます。
以下、サンプルコードです。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome import service as fs
# chromedriverのパスを指定
driver_path = "/Users/「PCのユーザ名」/Downloads/chromedriver"
chrome_service = fs.Service(executable_path=driver_path)
driver = webdriver.Chrome(service=chrome_service)
url = "https://www.google.com/?hl=ja"
driver.get(url)
# Google検索入力フォームに入力して送信
input_selector = "body > div.L3eUgb > div.o3j99.ikrT4e.om7nvf > form > div:nth-child(1) > div.A8SBwf > div.RNNXgb > div > div.a4bIc > input"
input_element = driver.find_element(by=By.CSS_SELECTOR, value=input_selector)
input_element.send_keys("プログラミング pythonのお部屋")
input_element.submit()
# 検索結果の記事情報はclass="yuRUbf"に入っている
class_group = driver.find_elements(by=By.CLASS_NAME, value="yuRUbf")
for elem in class_group:
title = elem.find_element(by=By.TAG_NAME, value="h3").text
url_link = elem.find_element(by=By.TAG_NAME, value="a").get_attribute("href")
print(title, url_link)
# driverを終了する
driver.quit()# 出力結果
pythonとは何か?プログラミング初心者向けの基本解説 - Schoo https://schoo.jp/biz/column/983
プログラミング言語 Python による 計測・制御入門 - 鳴門教育 ... http://www.naruto-u.ac.jp/facultystaff/ito/research-paper-public/2020/python-ev3-textbook.pdf
if文で条件に従って部屋を作ろう | デジケン https://kenchikku.com/archi-prog/py-a9/
koko-boのお部屋 - 兵庫県立教育研修所 https://dmzcms.hyogo-c.ed.jp/kenshusho/NC3/blogs/blog_entries/index/page:54?page_id=13&frame_id=15
新米プログラマーによるPython入門-サイコロ・おみくじ ... https://www.dice-programming-etc.com/python/
Pythonで作るIoTシステム プログラム・サンプル集 https://shop.cqpub.co.jp/hanbai/books/MTR/MTRZ202112.html
Pythonスタートブック - 246 ページ - Google ブック検索結果 https://books.google.co.jp/books?id=gKfh0uFMoLUC&pg=PA246&lpg=PA246&dq=%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%9F%E3%83%B3%E3%82%B0+python%E3%81%AE%E3%81%8A%E9%83%A8%E5%B1%8B&source=bl&ots=AYWVN9BmP7&sig=ACfU3U2a-JruJfSBNgk8TrgrIaczvnc8Sg&hl=ja&sa=X&ved=2ahUKEwjSwM25lIH1AhURZt4KHf7hCEQQ6AF6BAgmEAM
ラズパイピコと光センサー総額1150円で作る会議室の ... https://news.mynavi.jp/techplus/article/zeropython-80/
【コンビニ受取対応商品】 【送料無料】本/初めてのPython ... https://heldenbos.nl/savep.php?soapsudsybv/jie3510039.htm
Google検索で「プログラミング pythonのお部屋」と入力した場合の検索結果の記事タイトルと記事URLが取得できました。
それでは、具体的なseleniumライブラリの使い方を確認していきましょう。
seleniumライブラリの使い方
seleniumライブラリの使い方は、pythonからChromeDriverに動作してほしい処理をプログラムするイメージです。
まずはじめにダウンロードしたChromeDriverをpythonに読み込ませる処理を書き、その後、動作指示のプログラムを書いていきます。
ChromeDriverの読み込み
pythonにChromeDriverを読み込みます。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome import service as fs
# chromedriverのパスを指定
driver_path = "/Users/「PCのユーザ名」/Downloads/chromedriver"
chrome_service = fs.Service(executable_path=driver_path)
driver = webdriver.Chrome(service=chrome_service)基本的に上記のソースコードをコピペでOKですが、chromedriverのパスを正しく指定する必要があります。
先ほどダウンロードした「chromedriver」のパスをFinder(mac)もしくはエクスプローラー(Windows)からコピーします。
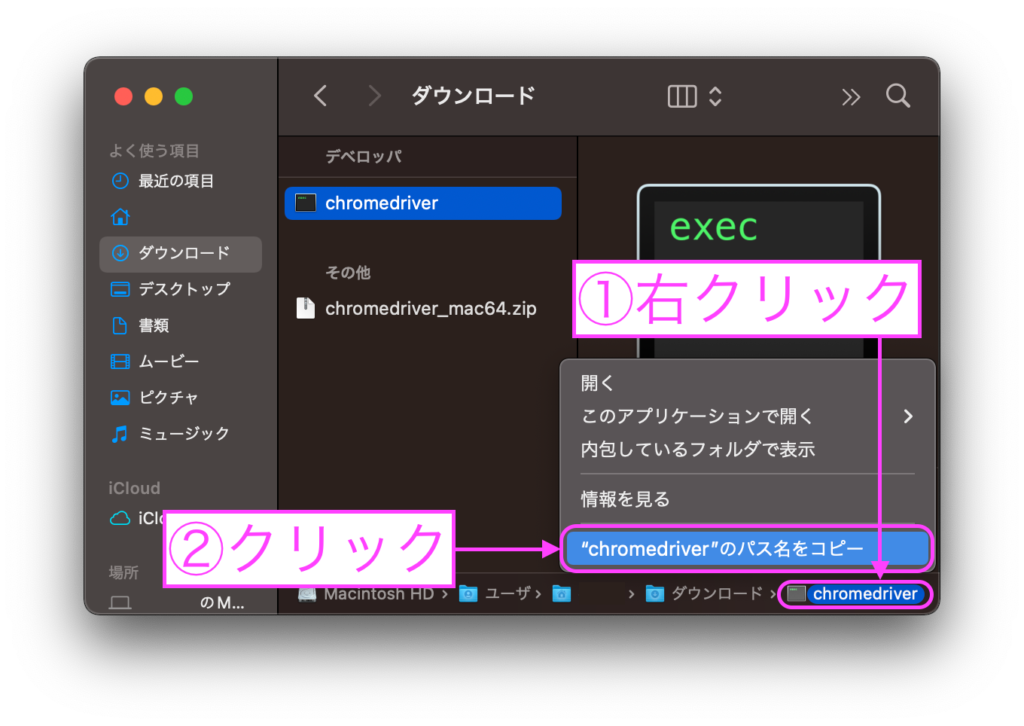
コピーしたパスを貼り付けてchromedriverのパスを指定しましょう。
Webサイトにアクセス get()メソッド
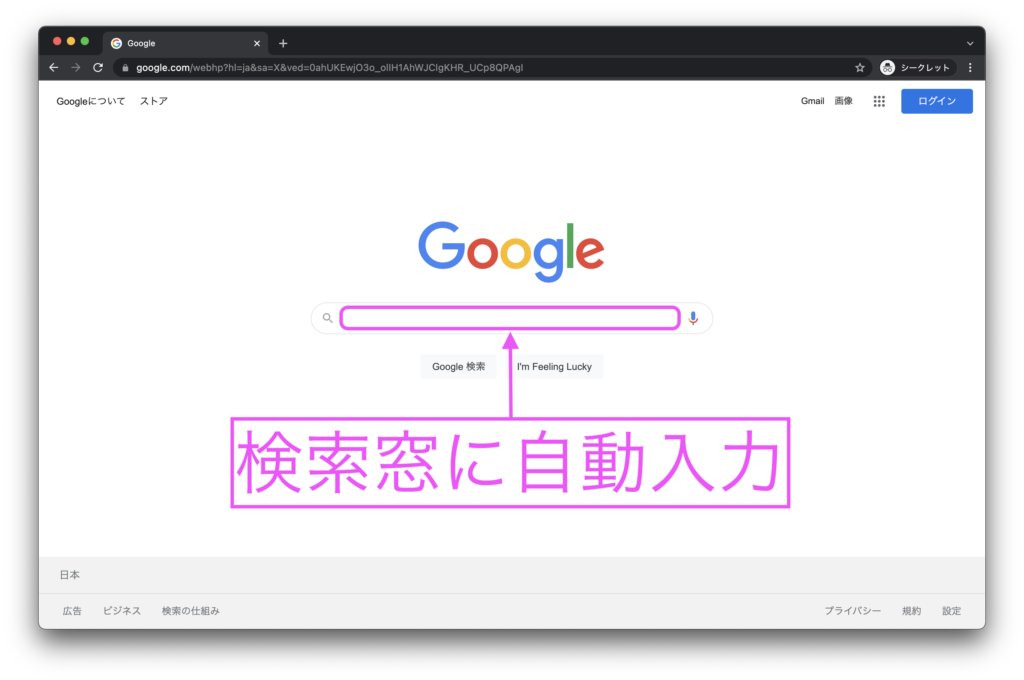
ChromeDriverで任意のWebサイトへアクセスするにはget()メソッドを使用します。
driver.get(url="アクセス先のURL文字列")
get()のカッコのなかにアクセス先にURLを指定することseleniumからWebページにアクセスできます。
# Google検索画面にアクセス(url: "https://www.google.com/?hl=ja")
url = "https://www.google.com/?hl=ja"
driver.get(url)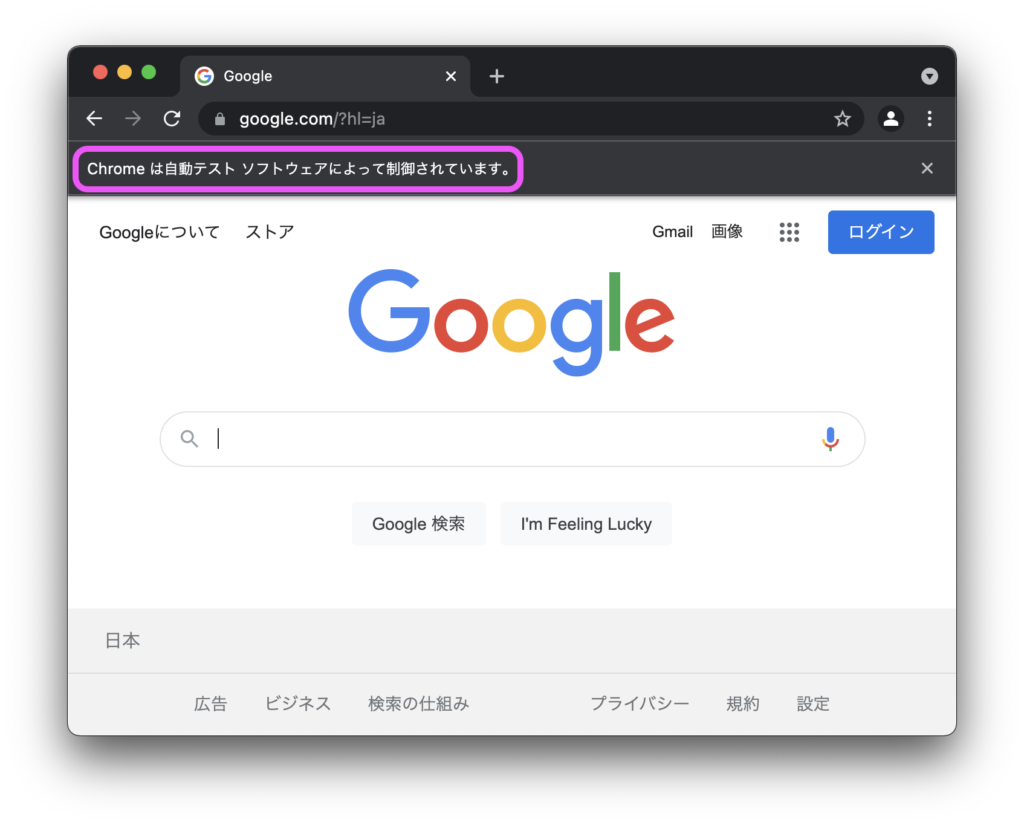
実行すると上図のようにブラウザが立ち上がり、アクセスしたサイトを表示してくれます。
左上に「Chromeは自動テストソフトウェアによって制御されています。」と表示されます。
もちろんurlを変更すれば任意のページにアクセス可能です。
html要素を一つだけ取得 find_element()メソッド
Webページのhtml要素をひとつだけ抽出・取得するにはfind_element()メソッドを使います。
find_element()メソッドの使い方 一覧
find_element()メソッドでは、さまざまな探索条件で要素を探すことができます。
従来の非推奨の抽出方法も併せて明記します。
| 抽出元 | 推奨 | 非推奨 |
|---|---|---|
| cssセレクタ | find_element(by=By.CSS_SELCTOR, value=cssセレクタ) | find_element_by_css_selector(cssセレクタ) |
| class属性 | find_element(by=By.CLASS, value=class名) | find_element_by_class_name(class名) |
| id属性 | find_element(by=By.ID, value=id名) | find_element_by_id(id名) |
| name属性 | find_element(by=By.NAME, value=name名) | find_element_by_name(name名) |
| タグ名 (h2タグ、aタグなど) | find_element(by=By.TAG_NAME, value=タグ名) | find_element_by_tag_name(タグ名) |
| XPath | find_element(by=By.XPATH, value=XPath) | find_element_by_xpath(XPath) |
| リンクテキスト | find_element(by=By.LINK_TEXT, value=リンクテキスト) | find_element_by_link_text(リンクテキスト) |
| 部分一致する リンクテキスト | find_element(by=By.PARTIAL_LINK_TEXT, value=リンクテキスト) | find_element_by_partial_link_text(リンクテキスト) |
ここでは、例としてGoogleの検索窓に文字列を入力するため、検索窓のhtml要素をcssセレクタから抽出してみましょう。
driver.find_element(by=抽出条件, value=抽出する値)
Chromeで「F12キー」もしくは「Webページ上で右クリック→検証」で下図のようにcssセレクタをコピーできます。
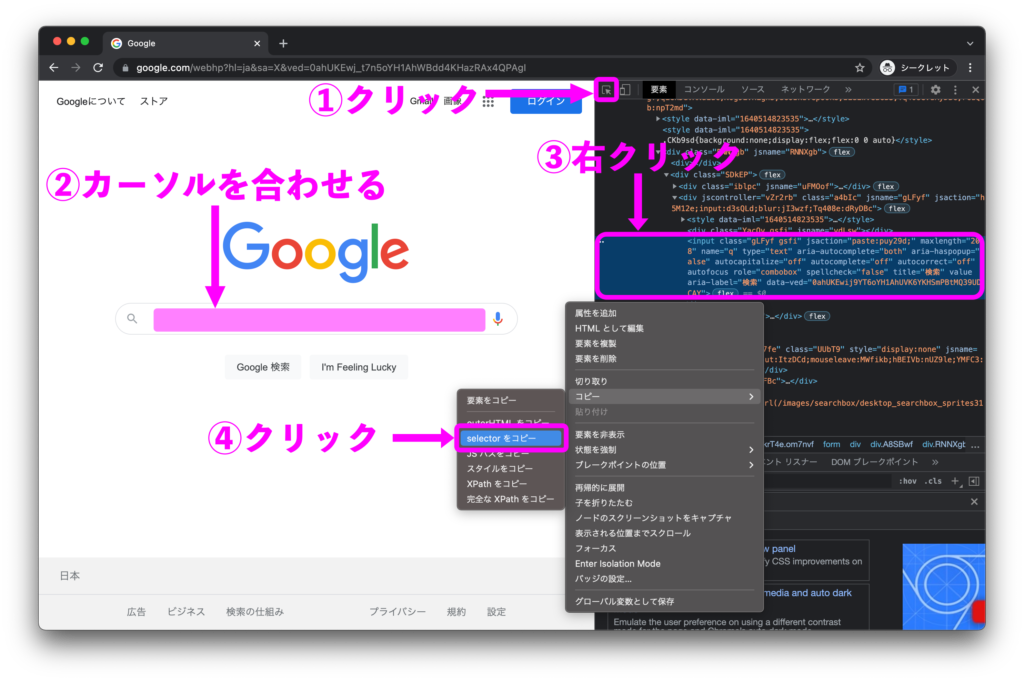
コピーしたcssセレクタを使用してseleniumライブラリでhtml情報を抽出します。
# Google検索入力フォームに入力して送信
input_selector = "body > div.L3eUgb > div.o3j99.ikrT4e.om7nvf > form > div:nth-child(1) > div.A8SBwf > div.RNNXgb > div > div.a4bIc > input"
input_element = driver.find_element(by=By.CSS_SELECTOR, value=input_selector)seleniumライブラリでhtml情報を抽出するには、find_element()もしくはfind_elements()メソッドを使用します。
ここでは検索窓のhtml情報が一つだけですので、find_element()メソッドを採用しています。
また、引数byでcssセレクタを、引数valueでcssセレクタの値を指定しています。
find_element()メソッドの引数byにselenium.webdriver.common.by.Byモジュールを使用します。
seleniumの最新バージョンではByモジュールを使用する書き方が推奨されています。
from selenium.webdriver.common.by import By
# OK
driver.find_element(by=By.CSS_SELECTOR, value=input_selector)
# NG(エラー)
## driver.find_element(by=CSS_SELECTOR, value=input_selector)
# 非推奨
driver.find_element_by_css_selector(input_selector)複数のhtml情報をまとめて一括で取得 find_elements()メソッド
find_elements()メソッドでは、特定条件を満たすhtml要素をまとめて一括で探すことができます。
使い方はfind_element()メソッドとほとんど同じです。
driver.find_elements(by=抽出条件, value=抽出する値)
find_elements()メソッドの使い方 一覧
find_elements()メソッドもfind_element()メソッドと使い方はほとんど同じです。
| 抽出元 | 推奨 | 非推奨 |
|---|---|---|
| cssセレクタ | find_elements(by=By.CSS_SELCTOR, value=cssセレクタ) | find_elements_by_css_selector(cssセレクタ) |
| class属性 | find_elements(by=By.CLASS, value=class名) | find_elements_by_class_name(class名) |
| id属性 | find_elements(by=By.ID, value=id名) | find_elements_by_id(id名) |
| name属性 | find_elements(by=By.NAME, value=name名) | find_elements_by_name(name名) |
| タグ名 (h2タグ、aタグなど) | find_elements(by=By.TAG_NAME, value=タグ名) | find_elements_by_tag_name(タグ名) |
| XPath | find_elements(by=By.XPATH, value=XPath) | find_elements_by_xpath(XPath) |
| リンクテキスト | find_elements(by=By.LINK_TEXT, value=リンクテキスト) | find_elements_by_link_text(リンクテキスト) |
| 部分一致する リンクテキスト | find_elements(by=By.PARTIAL_LINK_TEXT, value=リンクテキスト) | find_elements_by_partial_link_text(リンクテキスト) |
例として、Google検索結果のWebページからヒットした記事の一覧をすべてまとめて抽出してみましょう。
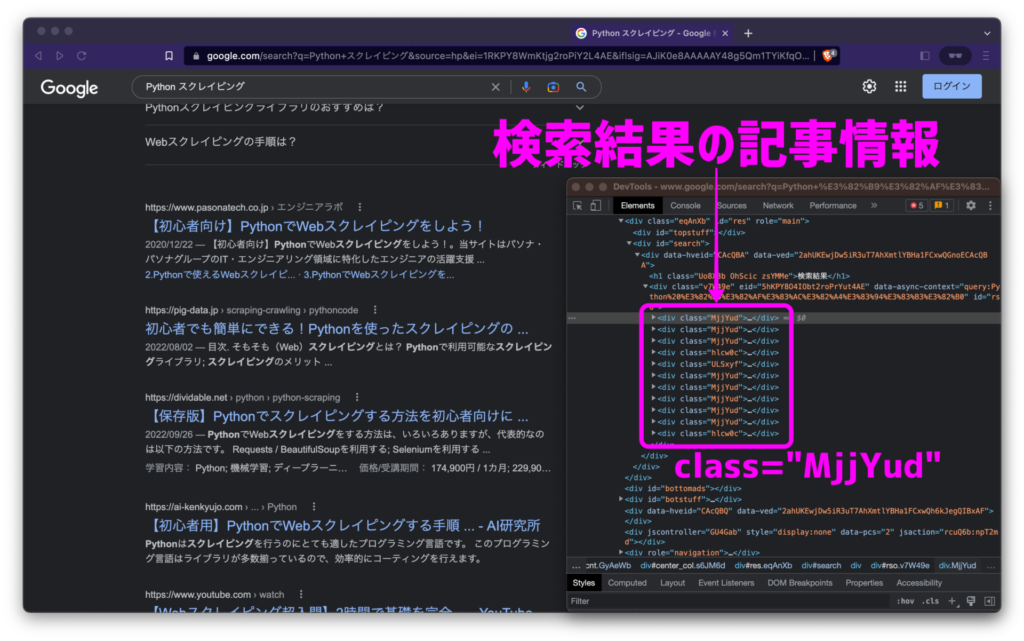
Google検索画面のhtml構造を見てみると、記事情報がclass="MjjYud"の同じclass属性で書かれているのがわかります。
これを利用して記事情報をfind_elements()メソッドを使ってまとめて一括で取得してみましょう。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome import service as fs
driver_path = "あなたのChromeDriverのインストール先のパス" # 例. "/Users/xxxxx/Downloads/chromedriver"
chrome_service = fs.Service(executable_path=driver_path)
driver = webdriver.Chrome(service=chrome_service)
url = "https://www.google.com/?hl=ja"
driver.get(url)
# Google検索入力フォームに入力して送信
input_selector = "body > div.L3eUgb > div.o3j99.ikrT4e.om7nvf > form > div:nth-child(1) > div.A8SBwf > div.RNNXgb > div > div.a4bIc > input"
input_element = driver.find_element(by=By.CSS_SELECTOR, value=input_selector)
input_element.send_keys("Python スクレイピング")
input_element.submit()
# 記事情報はclass="MjjYud"を満たすhtml要素をまとめて一括で取得
article_elements = driver.find_elements(by=By.CLASS_NAME, value="MjjYud")
# まとめて取得した要素から一つずつタイトルとURLを抽出して表示
for elem in article_elements:
try:
title = elem.find_element(by=By.TAG_NAME, value="h3").text
url_link = elem.find_element(by=By.TAG_NAME, value="a").get_attribute("href")
print(title, url_link)
except:
pass
# driverを終了する
driver.quit()出力結果
PythonでWebスクレイピングをする方法を解説!【入門編】 https://udemy.benesse.co.jp/development/python-work/web-scraping.html
図解!PythonでWEB スクレイピングを極めよう!(サンプル ... https://ai-inter1.com/python-webscraping/
【Python】スクレイピングの基本から実践 - チグサウェブ https://chigusa-web.com/blog/python%E3%81%A7%E7%B0%A1%E5%8D%98%E3%82%B9%E3%82%AF%E3%83%AC%E3%82%A4%E3%83%94%E3%83%B3%E3%82%B0/
https://legalmedia.coconala.com/3182
【初心者向け・保存版】PythonでWebスクレイピングして ... https://aiacademy.jp/media/?p=2116
【初心者向け】PythonでWebスクレイピングをしよう! https://www.pasonatech.co.jp/workstyle/column/detail.html?p=2638
初心者でも簡単にできる!Pythonを使ったスクレイピングの ... https://pig-data.jp/blog_news/blog/scraping-crawling/pythoncode/
【保存版】Pythonでスクレイピングする方法を初心者向けに ... https://dividable.net/programming/python/python-scraping
【初心者用】PythonでWebスクレイピングする手順 ... - AI研究所 https://ai-kenkyujo.com/programming/python/python-scraping-syoshinsya/
【Webスクレイピング超入門】2時間で基礎を完全 ... - YouTube https://www.youtube.com/watch?v=VRFfAeW30qE
面倒な「ブラウザ操作」や「データ収集」の作業はPythonで ... https://kino-code.com/python_automation_web_scraping/テキストボックスに入力 send_keys()メソッド
seleniumのsend_keys()メソッドを使えば、入力フォームやテキスト入力ボックスのようなhtml要素に文字列を書き込むことができます。
入力先のhtml要素.send_keys("入力する文字列")
ここでは一例として、Google検索窓に検索キーワードを入力してみましょう。
以下では、検索窓のhtml要素のinputタグとしてinput_elementを抽出済みである想定で、input_elementというhtml要素に対して「プログラミング」という文字列を入力させてみます。
send_keys()のカッコ内に入力したい文字列を指定すると、検索窓のhtml要素に入力できます。
# input_elementというhtml要素に「プログラミング」と入力
input_element.send_keys("プログラミング")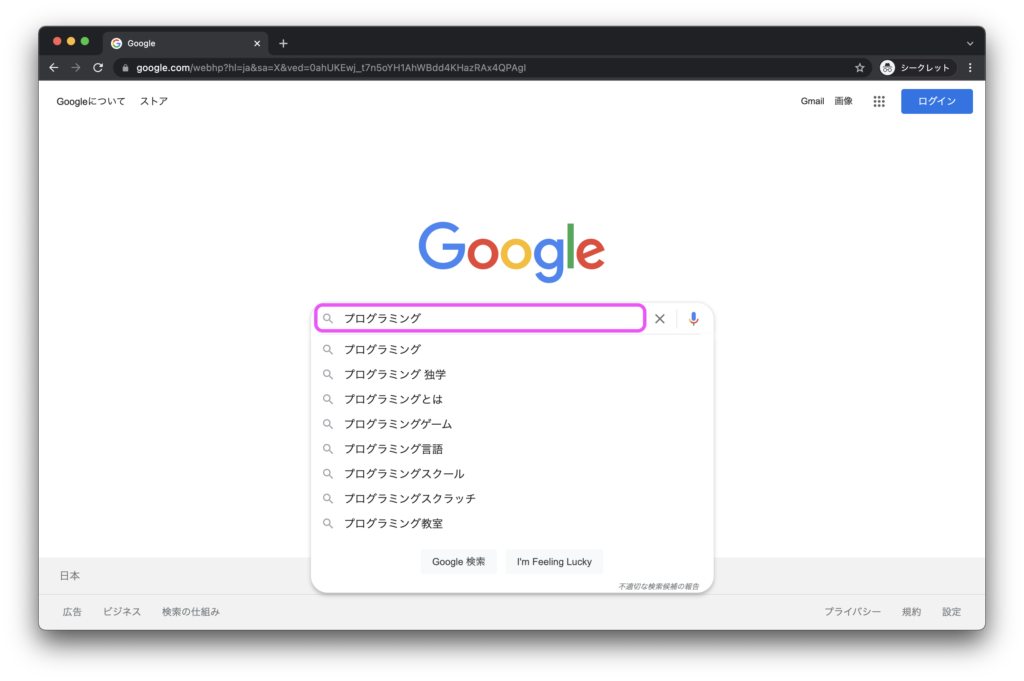
入力内容をクリア clear()メソッド
seleniumのclear()メソッドを使えば、send_keys()メソッドで入力した内容やWebページアクセス時にデフォルトで入力されている内容をクリア(削除)できます。
入力済みのhtml要素.clear()
# input_elementのhtml要素の入力内容をクリア(削除)
input_element.clear()入力フォームを送信 submit()メソッド
seleniumのsubmit()メソッドを使えば入力内容をカンタンに送信(POST)できます。
入力済みのhtml要素.submit()
submit()メソッドを使えるhtml要素は、文字列を入力するinputタグやtype="submit"のtype属性をもつinputタグです。
ここでは、一例として上記で「プログラミング」と入力した検索窓のhtml要素input_elementに対してsubmit()メソッドを適用すると検索結果の画面に遷移できます。
# 検索窓のhtml要素 input_elementへ入力済みの内容を送信
input_element.submit()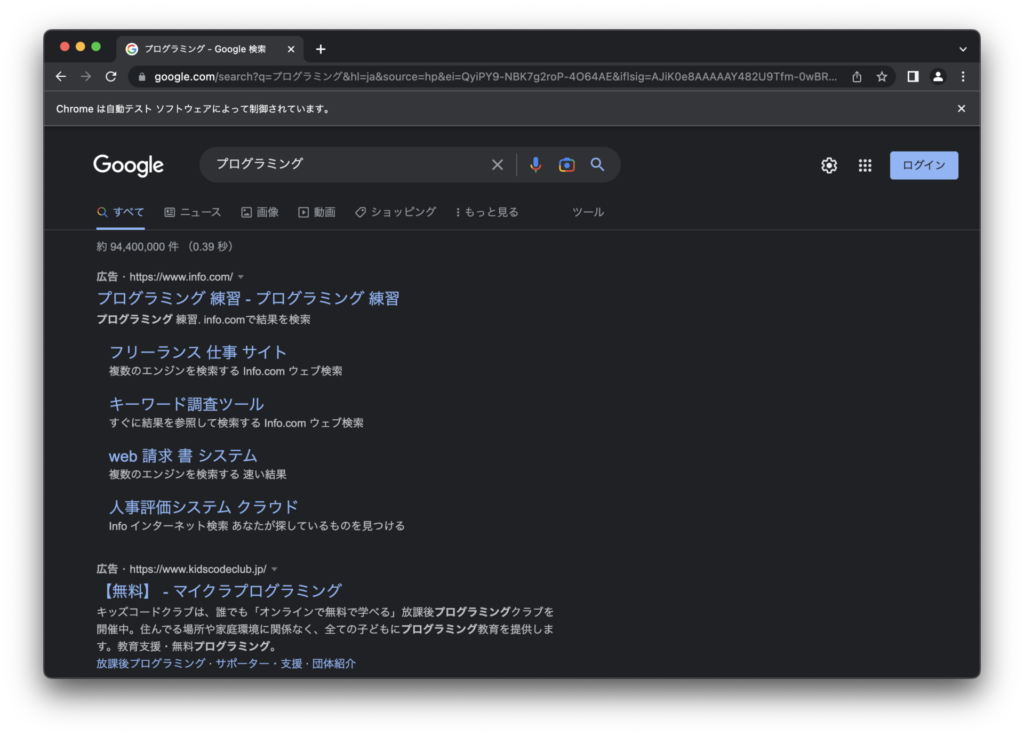
ブラウザ画面を表示させない headlessモード
seleniumでWebブラウザを操作させる際にheadlessモードを指定すると画面を非表示にできます。
デフォルトの設定ではseleniumライブラリでChromeDriverを操作する間、PC画面にChromeブラウザが動き回る様子が表示されます。
ブラウザ画面を非表示にする場合は、ヘッドレスモードという設定を指定します。
# ChromeDriverをヘッドレスモードで使用
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome import service as fs
chrome_service = fs.Service(executable_path=driver_path)
# 以下の3行でヘッドレスモードを指定
options = Options()
options.add_argument('--headless')
driver = webdriver.Chrome(service=chrome_service, options=options)
こちらを設定することで、ブラウザ画面が非表示のままプログラム処理を実行できます。
待機時間を明示的に指定 implicitly_wait()メソッド
seleniumでは、Webページにアクセスしてからhtml要素を読み込むまでの最低限の待機時間[秒]を指定できます。
ページ遷移直後にページ読み込み時間があることによって、本来存在するhtml要素をプログラムが見つけ出せずエラーが発生する場合があります。
implicity_wait()メソッドを使うと、読み込み遅延によるエラーを防ぐことできます。
driver.implicity_wait(time_to_wait=待機時間[sec])
# html情報を見つけ出す際の最低限の待ち時間(秒数)を指定
driver.implicitly_wait(time_to_wait=3.0)このようにimplicitly_wait()メソッドを用いて待ち時間を秒数で指定できます。
ブラウザ画面を最大化 maximize_window()メソッド
seleniumではブラウザを立ち上げた際にウィンドウサイズが1200×830となっています。
maximize_window()メソッドを使って画面を最大化してみましょう。
driver.maximize_window()
起動したブラウザ画面を最大化してみます。
# ブラウザ画面を最大化
driver.maximize_window()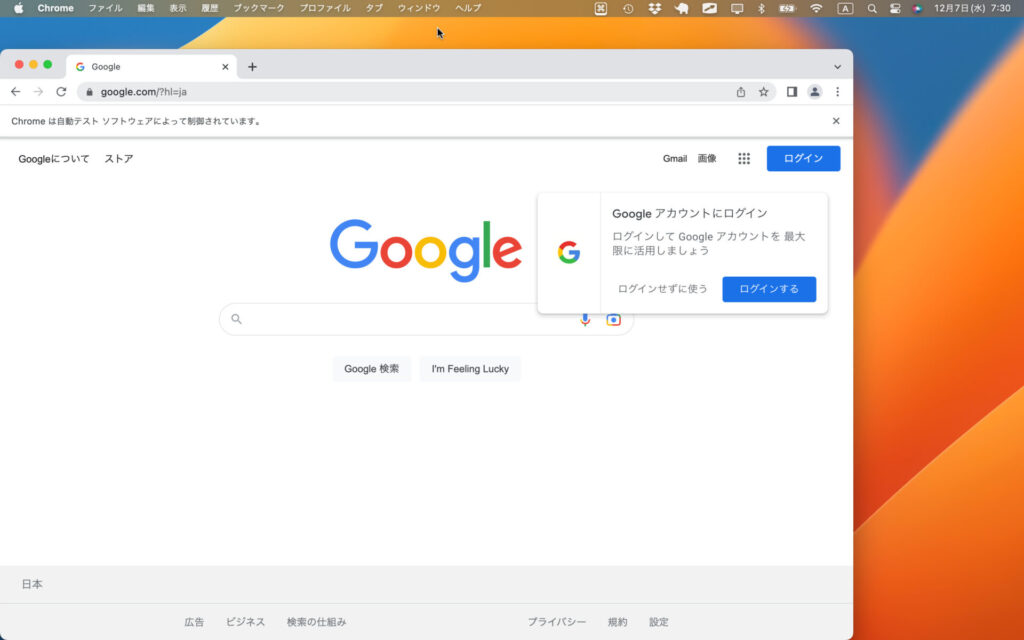
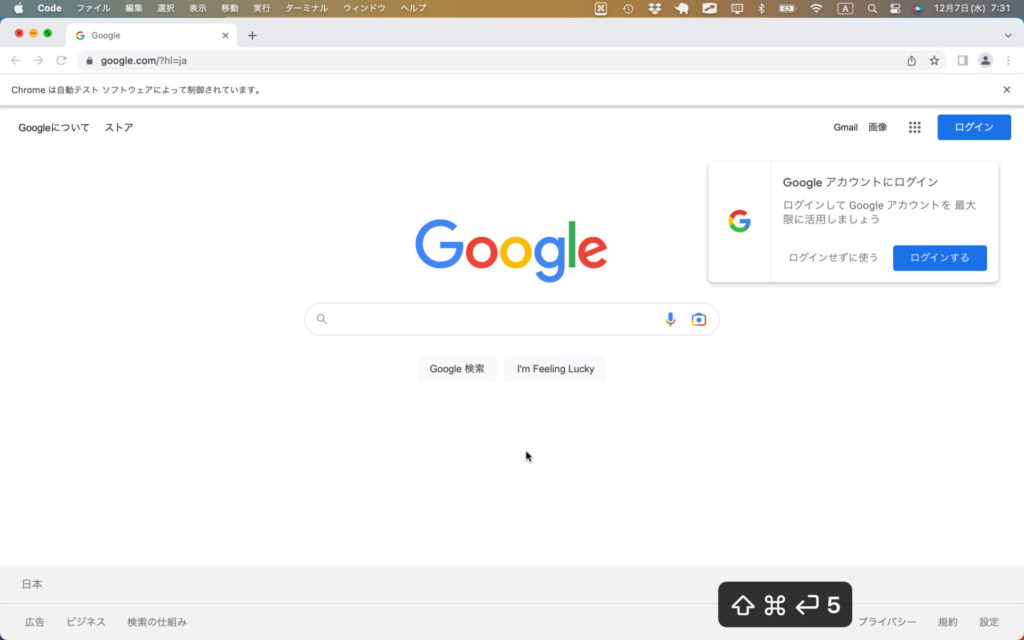
ウィンドウサイズを取得 get_window_size()メソッド
seleniumのget_window_size()メソッドを使えば起動しているウィドウサイズを取得・確認できます。
driver.get_window_size()
ここでは上で画面サイズを最大化した後の画面サイズを確認してみましょう。
# ウィンドウサイズを取得・確認
window_size = driver.get_window_size()
print(window_size)出力結果
{'width': 1440, 'height': 875}任意のウィンドウサイズに変更する set_window_size()メソッド
seleniumのset_window_size()メソッドを使えばウィンドウサイズを自由に変更できます。
driver.set_window_size(width=横幅[ピクセル], height=高さ[ピクセル])
例として横幅200ピクセル、高さ150ピクセルで指定してみましょう。
# ウィンドウサイズを横幅200ピクセル、高さ150ピクセルに指定
driver.set_window_size(width=200, hight=150)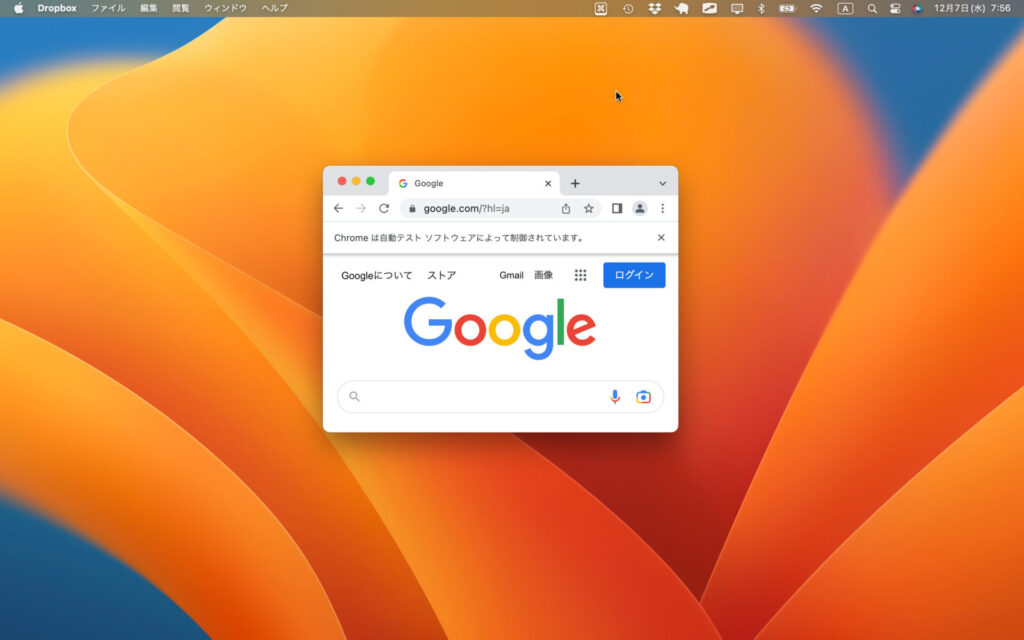
要素のクリック click()メソッド
seleniumのclick()メソッドを使えばリンク付き文字列やボタンなどをクリックできます。
html要素.click()
例としてGoogleトップページにアクセスし、ログインボタンの要素を探索してクリックさせてみましょう。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome import service as fs
driver_path = "あなたのChromeDriverのインストール先のパス" # 例. "/Users/xxxxx/Downloads/chromedriver"
chrome_service = fs.Service(executable_path=driver_path)
driver = webdriver.Chrome(service=chrome_service)
url = "https://www.google.com/?hl=ja"
driver.get(url)
# ログインボタンのhtml要素をCSSセレクタで探索
login_button_element = driver.find_element(by=By.CSS_SELECTOR, value="#gb > div > div.gb_We > a")
# ログインボタンのhtml要素をクリック
login_button_element.click()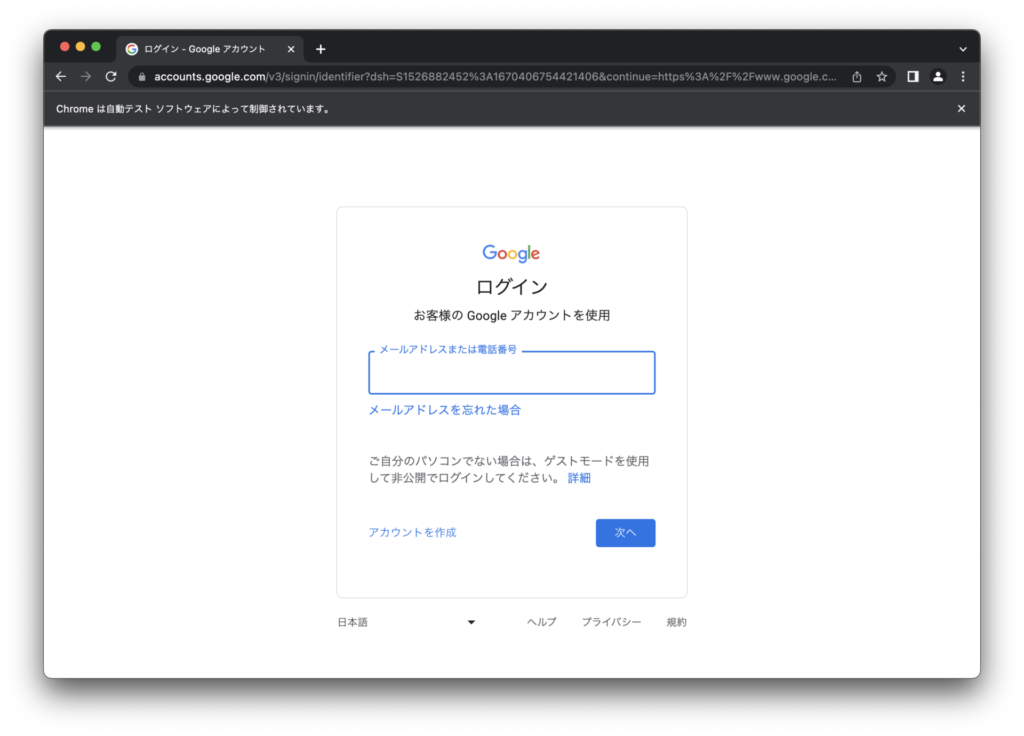
このようにログインボタンをクリックした先のページに移動できました。
ページの再読み込み refresh()メソッド
seleniumのrefresh()メソッドを使えば、表示しているWebページを再読み込みできます。
driver.refresh()
起動したブラウザをすべて終了 quit()メソッド
seleniumでの処理がひと通り終わったら、quit()メソッドでブラウザをすべて終了できます。
driver.quit()
通常利用しているブラウザはそのまま操作し続けることができますよ。
例えるなら以下の画像のようなアプリケーションの終了と同じ処理です。
操作中のブラウザを閉じる close()メソッド
seleniumで操作しているブラウザを一つだけ閉じるにはclose()メソッドを使います。
driver.close()
まとめ
今回はseleniumライブラリを使ったWebスクレイピングの実装方法を具体的に紹介しました。
ぜひあなたもオリジナルのWebスクレイピングを試してみてください。


