
本ページには PR が含まれます。

seleniumを使ったスクレイピングで
Web上の画像の取得・保存ってどうやるの…?
今回はseleniumライブラリを使ったWebスクレイピングで、Web上の画像データを取得・保存する方法を解説します。
サンプルコードと処理の流れを見ながら、サクサク処理を試せるのでぜひ参考にしてみてください。
seleniumライブラリのくわしい使い方を知りたい方はこちら!!

Pythonの実践的なWebスクレイピング技術について学びたいという方に向けてUdemy学習コースを公開しています。
\10/27(金)までの 90%OFFクーポンで Webスクレイピングを学べる!!/
30日間返金保証!
すぐにでもスクレイピング技術を活かせるようになりますよ!
ライブラリのインストール
Webスクレイピングの実装に必要なseleniumライブラリとwebdriver-managerをインストールします。
下記のコマンドをコマンドプロンプト(Windows)もしくはターミナル(macOS)で実行しましょう。
pip install selenium
pip install webdriver-manager==3.5.3コンソールの最終行に「Successfully Installed ~~~」と表示されていればインストールは完了です。
webdriver-mangerライブラリはバージョンによってバグが残っていることがあるためver. 3.5.3をインストール
webドライバーの起動
seleniumライブラリをインストールできたら、PythonでWebブラウザを自動操作させていきましょう。
chromeのWebブラウザを起動してみます。
サンプルコード
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# 最新のchromeドライバーをインストールして、インストール先のローカルパスを取得
driver_path = ChromeDriverManager().install()
# chromeドライバーのあるパスを指定して、起動
driver = webdriver.Chrome(service=Service(executable_path=driver_path))実行結果
Webページにアクセス
初めに取得した画像が公開されているWebページにアクセスします。
seleniumライブラリのget()メソッドを使って、Webページにアクセスしましょう。
driver.get(url=アクセス先のURL)
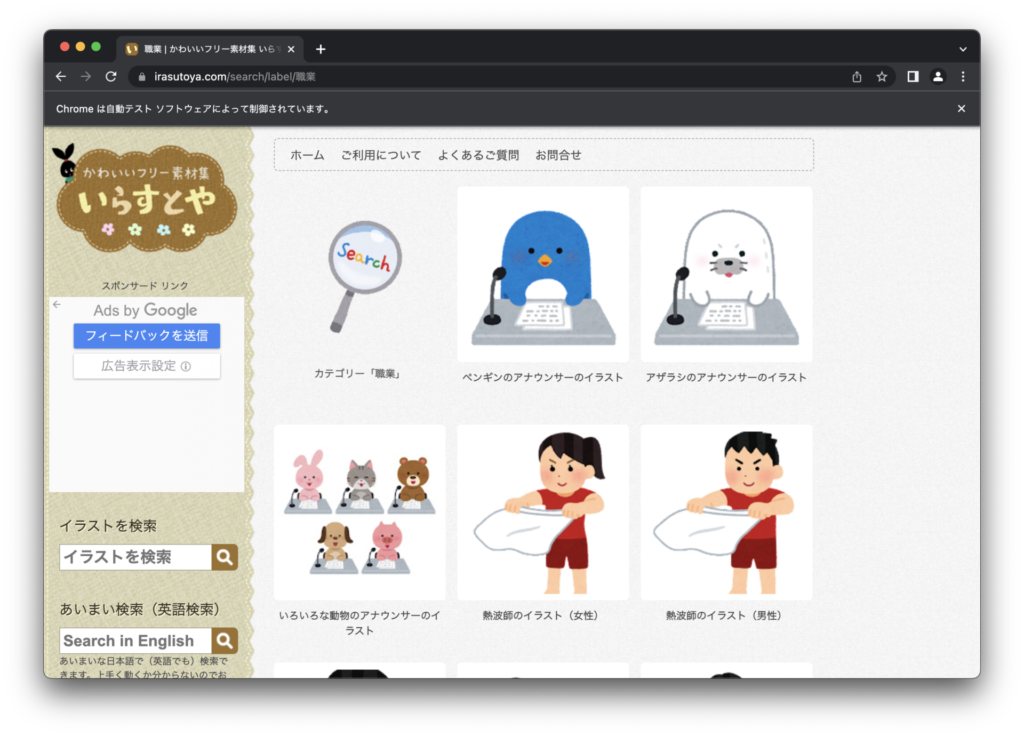
ここでは、例として「いらすとや」のWebページから画像データを取得していきます。
サンプルコード
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# 最新のchromeドライバーをインストールして、インストール先のローカルパスを取得
driver_path = ChromeDriverManager().install()
# chromeドライバーのあるパスを指定して、起動
chrome_service = Service(executable_path=driver_path)
# 「いらすとや」のWebページにアクセス
url = "https://www.irasutoya.com/search/label/%E8%81%B7%E6%A5%AD"
driver.get(url=url)実行結果
画像のWeb要素を取得
Webページ上の情報から画像のWeb要素を取得します。
WebページのHTML情報を参照して、画像のWeb要素を取得します。
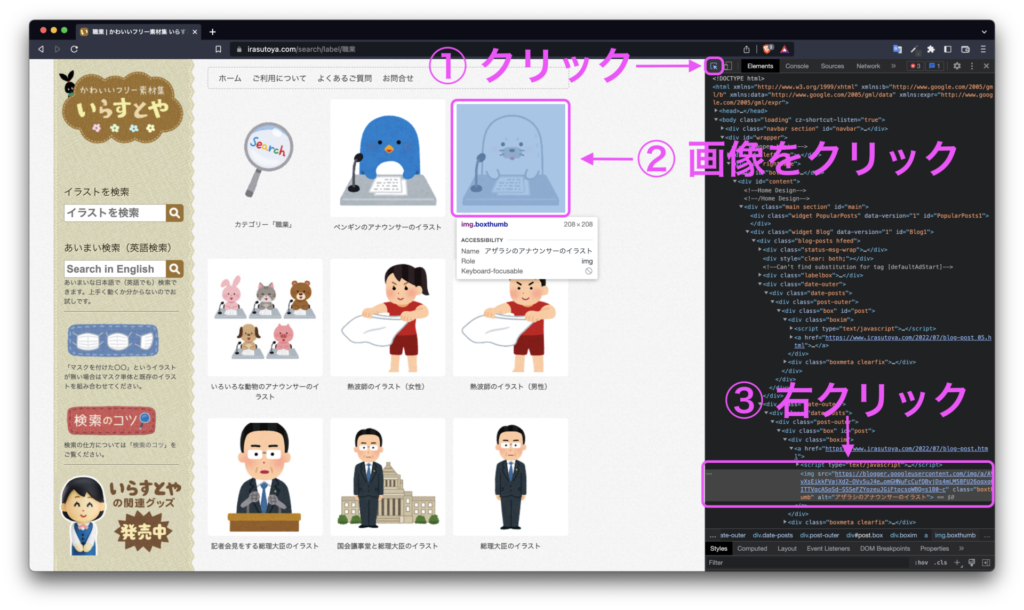
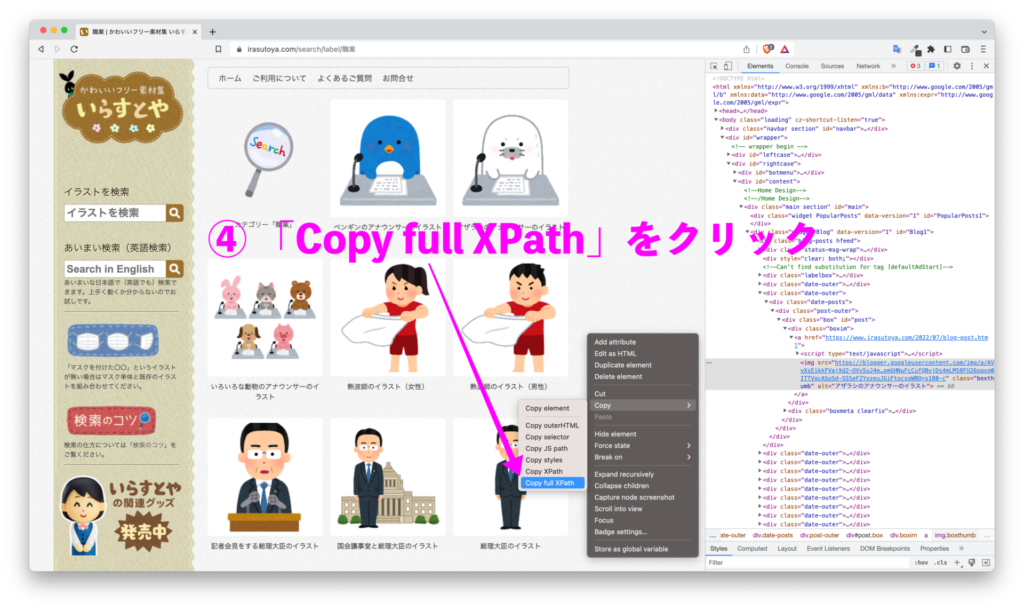
サンプルコード
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# 最新のchromeドライバーをインストールして、インストール先のローカルパスを取得
driver_path = ChromeDriverManager().install()
# chromeドライバーのあるパスを指定して、起動
chrome_service = Service(executable_path=driver_path)
# 「いらすとや」のWebページにアクセス
url = "https://www.irasutoya.com/search/label/%E8%81%B7%E6%A5%AD"
driver.get(url=url)
# コピーしたXPathを使って画像のWeb要素を取得
xpath = "/html/body/div[2]/div[2]/div[2]/div/div[2]/div[1]/div[5]/div/div/div/div[1]/a/img"
element = driver.find_element(by=By.XPATH, value=xpath)
# 取得した画像のHTML情報を表示
print(element.get_attribute("outerHTML"))
# Webドライバーの終了
driver.quit()出力結果
<img src="https://blogger.googleusercontent.com/img/a/AVvXsEikkFVajXd2-OVv5uJ4eypeqALxjVJlTmiHfI-VKeDS-BA3CzuupG89RFvGLFSfX8ujudJA4rj5yMIkMK247QMh5tCGsyHalbM08FSjwUNajIneRz0qWy4C-EBomGHNuFcCufQBvjDs4mLM58FU26oqxq0ITTVqcASoSd-SSSeFZYozeuJGiFtocsoWBQ=s180-c" class="boxthumb" alt="アザラシのアナウンサーのイラスト">imgタグから画像のURLを取得
上で取得したWeb要素(imgタグ)からsrc属性値を取り出してURLを取得しましょう。
seleniumのget_attribute()メソッドを使えば、web要素から好きな属性値を取り出せます。
web要素.get_attribute(name="src")
サンプルコード
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# 最新のchromeドライバーをインストールして、インストール先のローカルパスを取得
driver_path = ChromeDriverManager().install()
# chromeドライバーのあるパスを指定して、起動
chrome_service = Service(executable_path=driver_path)
# 「いらすとや」のWebページにアクセス
url = "https://www.irasutoya.com/search/label/%E8%81%B7%E6%A5%AD"
driver.get(url=url)
# コピーしたXPathを使って画像のWeb要素を取得
xpath = "/html/body/div[2]/div[2]/div[2]/div/div[2]/div[1]/div[5]/div/div/div/div[1]/a/img"
element = driver.find_element(by=By.XPATH, value=xpath)
# Web上の画像URLを取得
img_url = element.get_attribute("src"))
print(img_url)
# Webドライバーの終了
driver.quit()出力結果
https://blogger.googleusercontent.com/img/a/AVvXsEikkFVajXd2-OVv5uJ4eypeqALxjVJlTmiHfI-VKeDS-BA3CzuupG89RFvGLFSfX8ujudJA4rj5yMIkMK247QMh5tCGsyHalbM08FSjwUNajIneRz0qWy4C-EBomGHNuFcCufQBvjDs4mLM58FU26oqxq0ITTVqcASoSd-SSSeFZYozeuJGiFtocsoWBQ=s180-cこのURLにアクセスすると下図のように、指定した画像を確認できます。
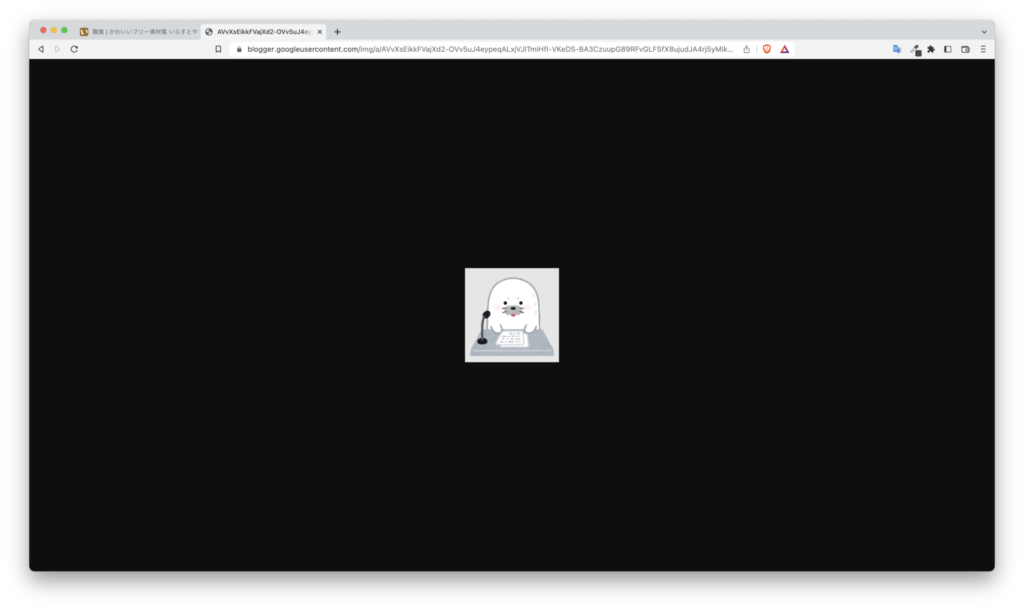
画像をローカルPCに保存
Web上にURLで公開されている画像を、一度バイナリデータに変換してローカルPC上に書き込むことで保存できます。
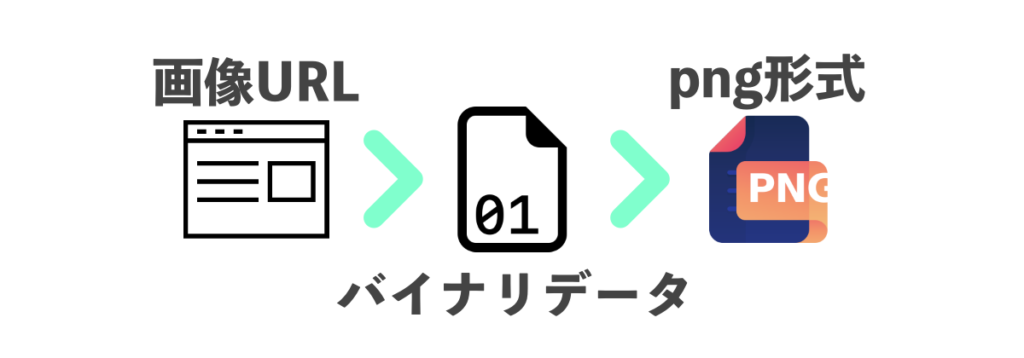
ここでは、以下の流れに沿って画像URLからpngファイルを保存します。
- urllibライブラリで画像URLにアクセスして画像バイナリデータを読み込み
- Pythonのwith open()構文を使ってバイナリデータからpngファイルを書き出す
サンプルコード
# urllibライブラリを使って画像URLからバイナリ読み込む
with urllib.request.urlopen(img_ulr)as rf:
img_data = rf.read()
# with open()構文を使ってバイナリデータをpng形式で書き出す
with open("irasutoya.png", mode="wb")as wf:
wf.write(img_data)実行結果
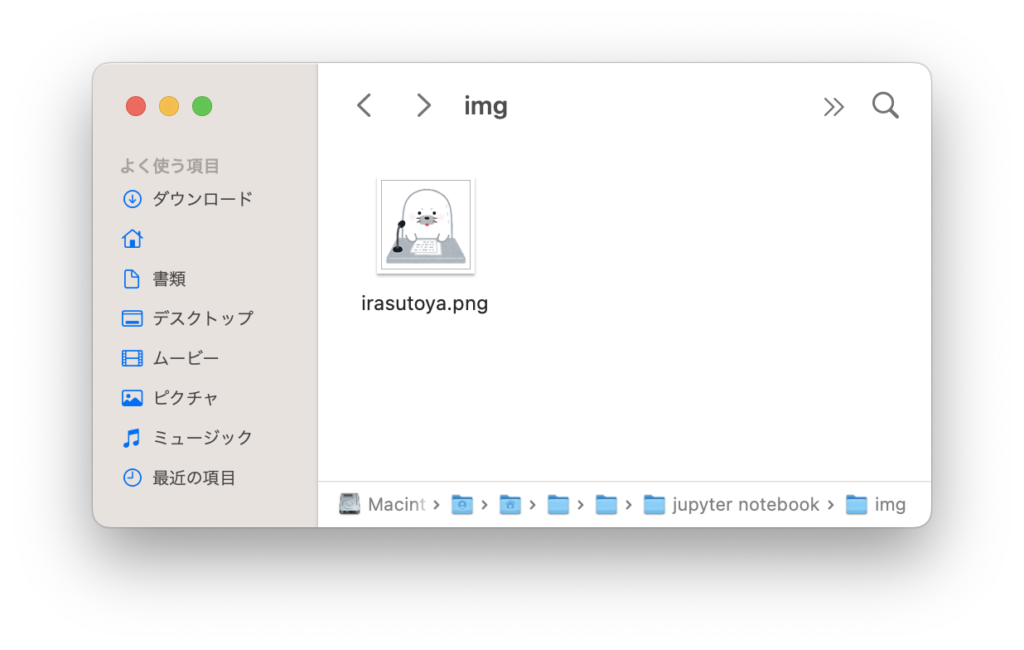
まとめ
seleniumライブラリを使ったWebスクレイピングで、Web上の画像データを取得・保存する方法を紹介しました。
Webスクレイピングをマスターすると、情報収集が圧倒的にラクになります。
- 仕事で毎日行うデータ収集
- 予約サービスへの自動登録・応募
- ショッピングサイトの価格監視
などなど、さまざまな分野で応用できます。
PythonのWebスクレイピング技術を体系的に学びたい、という方に向けてUdemyで動画学習コースを公開しているので、ぜひ活用してみてください!!
\Webスクレイピング技術を動画で一気に学べる!!/
Webスクレイピングで日々の作業を自動化し、より有意義な時間を増やしましょう!!

