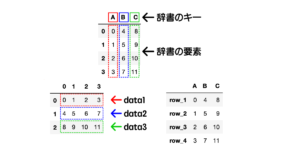
この記事ではpandasライブラリにおけるDataFrameを結合(merge, join, concat)する方法を具体的に解説します。
サンプルコードをコピペしながらサクサク処理を試せますので、 ぜひ活用してみてください。
pandasのDataFrame結合
pandasにおいてDataFrameを結合する方法は大きく3種類存在します。
列名をキーとして結合
pd.merge()
pd.DataFrame.merge()
インデックスをキーとして結合
pd.DataFrame.join()
DataFrameを連結
pd.concat()
この記事ではpd.merge(), pd.DataFrame.merge()での結合方法を具体的に紹介します。
pd.merge(), pd.DataFrame.merge()の使い方
pd.merge(), pd.DataFrame.merge()での結合において、指定する引数は基本的に同じです。
複数のDataFrameを結合する際、共通の列名をを持つ場合、持たない場合が考えられます。
これらを場合分けで解説していきます。
共通の列名を持つDataFrameの結合
共通の列名col_cを持つ2つのDataFrameを結合してみましょう。
import pandas as pd
# 2つのDataFrameを作成(共通の列col_aを持つ)
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]})
df2 = pd.DataFrame({"col_c": ["c", "cc", "C", "CC", "cC"], "col_y": ["y", "yy", "Y", "YY", "yY"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]})
# df1とdf2を結合(pd.merge()メソッドで結合)
df3 = pd.merge(df1, df2)
# df1とdf2を結合(pd.DataFrame.merge()メソッドで結合)
df3 = df1.merge(df2)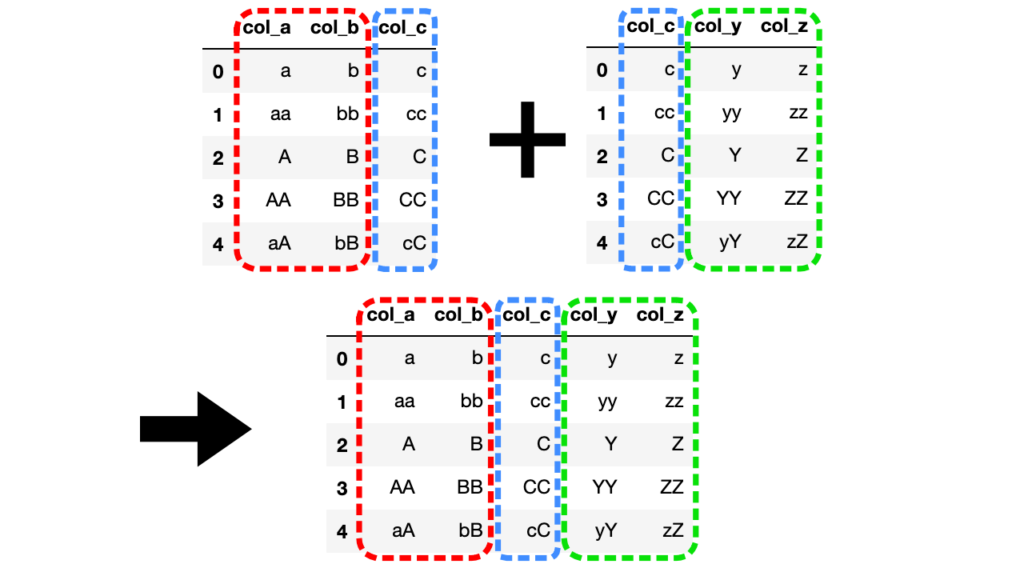
列名col_cをもつdf1とdf2を結合して新たなdf3を作成しました。
pd.merge()で結合する場合は引数に結合したいDataFrameを、
pd.DataFrame.merge()で結合する場合はDataFrameに対して直接.merge()を適用して引数に結合したいDataFrameを指定します。
キーとなる列名を指定(on)
結合するDataFrameの中に共通する列名が2つ以上ある場合、キーとなる列名を明示的に指定できます。
まずは、引数onにNone(デフォルト)を指定した場合を見てみましょう。
import pandas as pd
# 2つのDataFrameを作成(共通の列col_b, col_cを持つ)
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]})
df2 = pd.DataFrame({"col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]})
# キーとなる列名を指定しない(引数on=None)
## pd.merge()メソッドで結合
df3 = pd.merge(df1, df2, on=None)
## pd.DataFrame.merge()メソッドで結合
df3 = df1.merge(df2, on=None)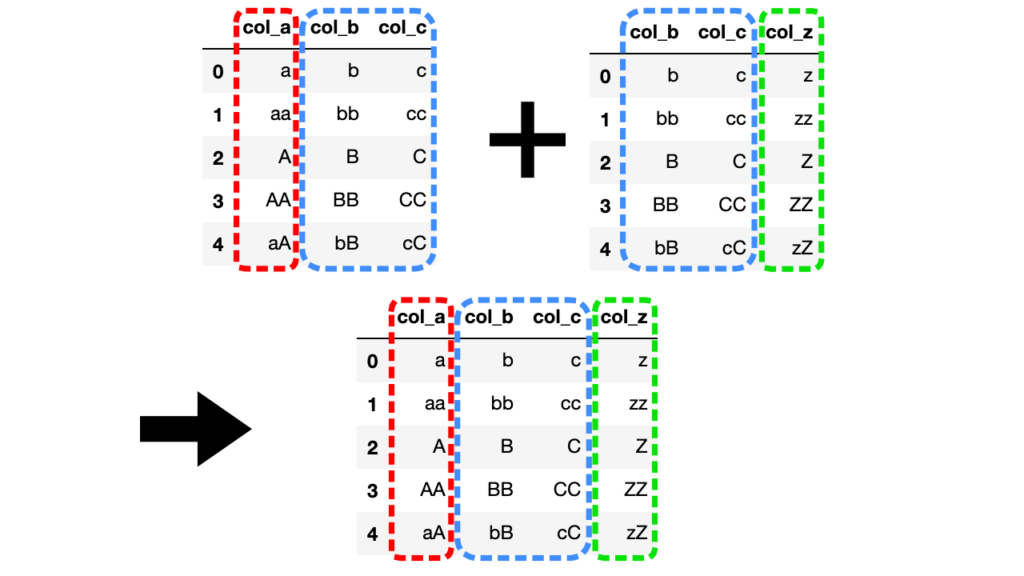
共通するすべての列がそのまま結合されており、共通列が1つの場合と同様の結合の仕方になります。
次に、引数onに"col_b"を指定した場合を見てみましょう。
import pandas as pd
# 2つのDataFrameを作成(共通の列col_b, col_cを持つ)
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]})
df2 = pd.DataFrame({"col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]})
# キーとなる列名を"col_b"と指定(引数on="col_b")
## pd.merge()メソッドで結合
df3 = pd.merge(df1, df2, on="col_b")
# df1とdf2を結合(pd.DataFrame.merge()メソッドで結合)
df3 = df1.merge(df2, on="col_b")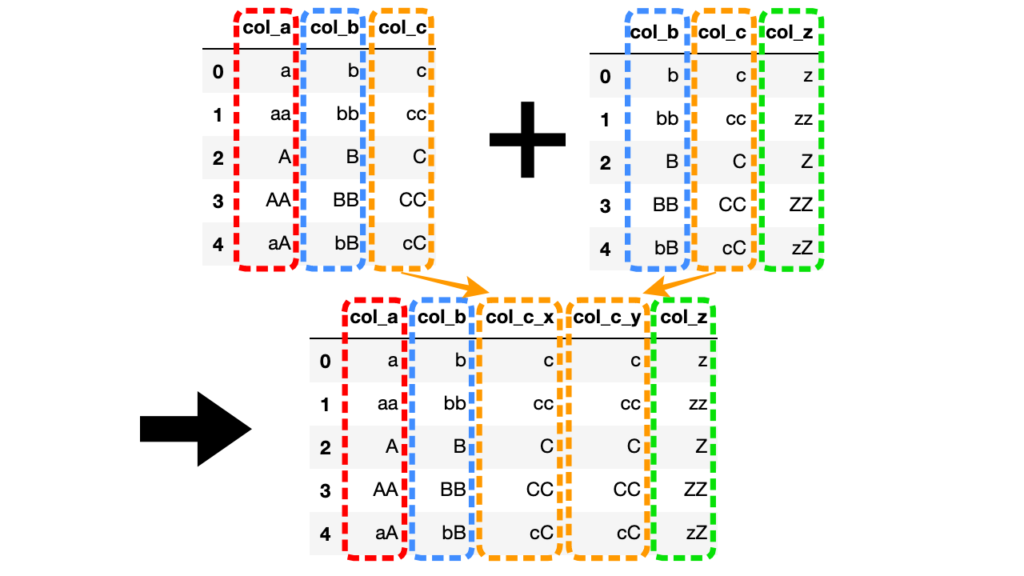
引数onで指定したcol_bは結合後ひとつにまとまっていますが、指定していない方の共通列col_cが新たに列col_c_x, col_c_yとなって生成されています。
共通列が複数ある場合は、明示的にキーとなる列名を引数onに指定することでその他の共通列を残したまま結合できます。
ここで、残した共通列col_cに自動的にcol_c_x, col_c_yという列名が付与(サフィックス)されましたが、付与させる文字列を指定することもできます。
サフィックスの指定(suffixes)
import pandas as pd
# 2つのDataFrameを作成(共通の列col_b, col_cを持つ)
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]})
df2 = pd.DataFrame({"col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]})
# サフィックスをそれぞれ"_A", "_B"と指定(引数suffixes=["_A", "_B"])
## pd.merge()メソッドで結合
df3 = pd.merge(df1, df2, on="col_b", suffixes=["_A", "_B"])
## pd.DataFrame.merge()メソッドで結合
df3 = df1.merge(df2, on="col_b", suffixes=["_A", "_B"])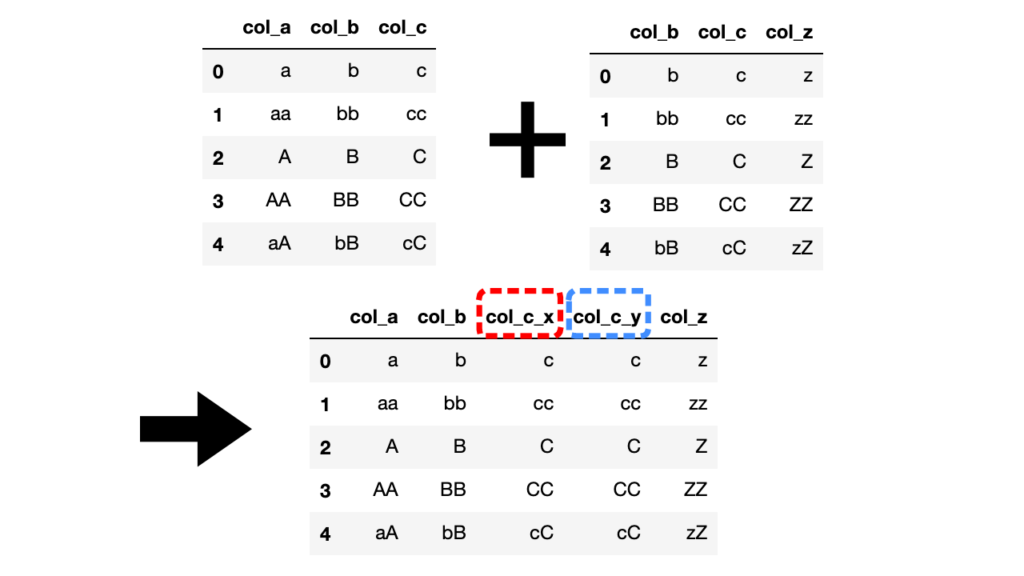
suffixes=["_x", "_y"])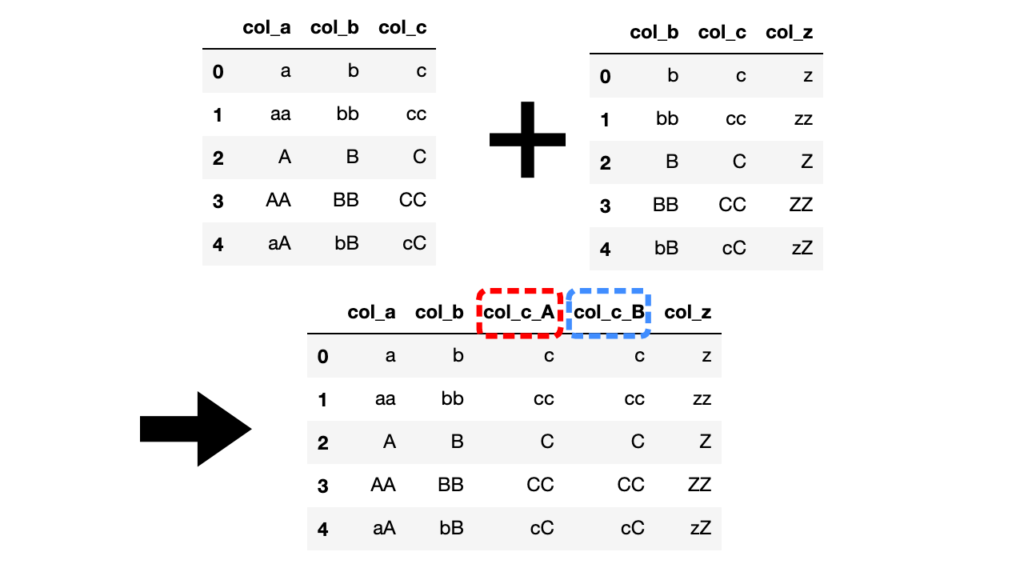
suffixes=["_A", "_B"]共通の列名を持たないDataFrameの結合
左側&右側キー列を指定(left_on, right_on)
共通の列名を持たないDataFrameどうしの結合では、
左側DataFrameのキーとなる列名(left_on)、右側DataFrameのキーとなる列名(right_on)をそれぞれ指定します。
例を見てみましょう。
import pandas as pd
# 2つのDataFrameを作成(共通の列名を持たない)
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]})
df2 = pd.DataFrame({"col_a'": ["a'", "a'a'", "A", "AA", "a'A"], "col_y": ["y", "yy", "Y", "YY", "yY"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]})
# 左側を列名"col_a"、右側を列名"col_a'"と指定
## pd.merge()メソッドで結合
df3 = pd.merge(df1, df2, left_on="col_a", right_on="col_a'")
## pd.DataFrame.merge()メソッドで結合
df3 = df1.merge(df2, left_on="col_a", right_on="col_a'")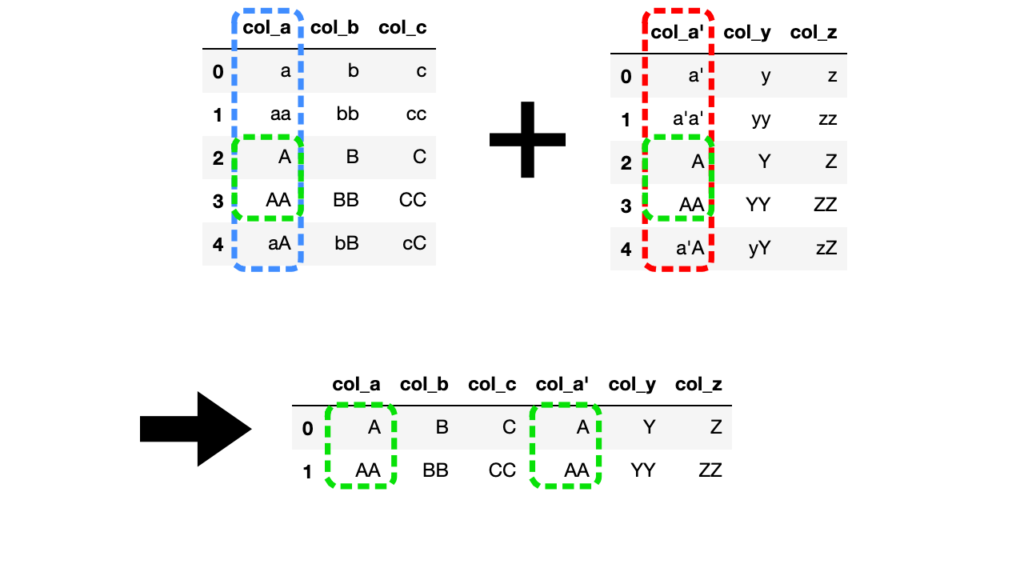
左側と右側で指定した列名どうしを基準にDataFrameを結合します。
ここでは、共通の値が入っている行のみが残っていますが、結合方法によって他の行を残すことができます。
結合方法を指定(how)
指定可能な結合方法は主に以下の4つです。
内部結合(デフォルト)
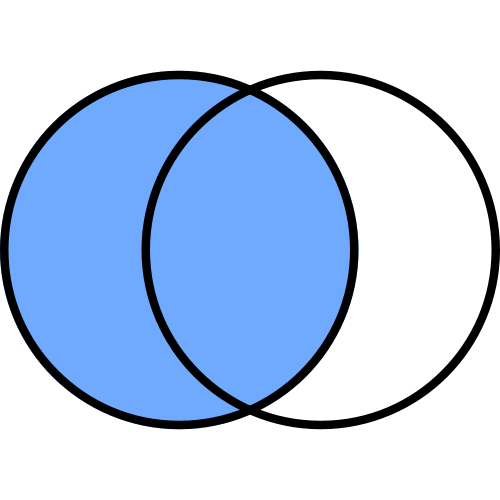
左外部結合
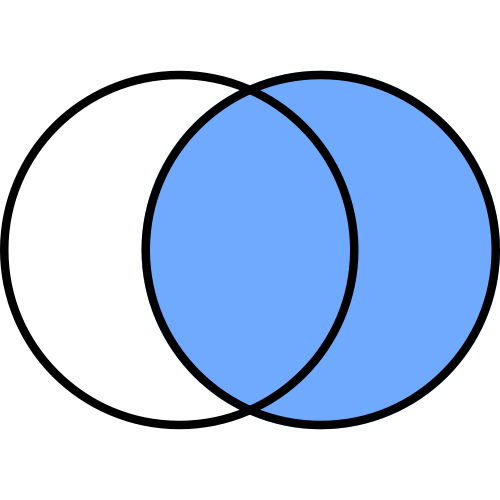
右外部結合
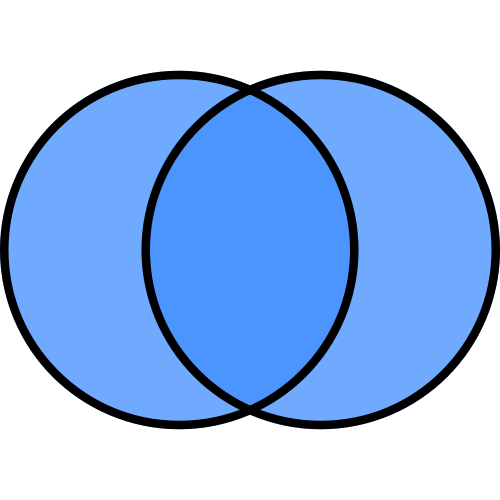
完全外部結合
内部結合(inner)
複数のDataFrameの共通部分だけを残すように結合する方法です。
import pandas as pd
# 2つのDataFrameを作成(共通の列名を持たない)
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]})
df2 = pd.DataFrame({"col_a'": ["a'", "a'a'", "A", "AA", "a'A"], "col_y": ["y", "yy", "Y", "YY", "yY"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]})
# 内部結合(デフォルト)を指定(引数how="inner")
## pd.merge()メソッドで結合
df3 = pd.merge(df1, df2, how="inner", left_on="col_a", right_on="col_a'")
## pd.DataFrame.merge()メソッドで結合
df3 = df1.merge(df2, how="inner", left_on="col_a", right_on="col_a'")デフォルトの内部結合をそのまま指定したので、先ほどと全く同じ結果が得られます。
左外部結合(left)
左外部結合では左側DataFrameに右側DataFrameを足す形になります。
import pandas as pd
# 2つのDataFrameを作成(共通の列名を持たない)
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]})
df2 = pd.DataFrame({"col_a'": ["a'", "a'a'", "A", "AA", "a'A"], "col_y": ["y", "yy", "Y", "YY", "yY"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]})
# 左外部結合を指定(引数how="left")
## pd.merge()メソッドで結合
df3 = pd.merge(df1, df2, how="left", left_on="col_a", right_on="col_a'")
## pd.DataFrame.merge()メソッドで結合
df3 = df1.merge(df2, how="left", left_on="col_a", right_on="col_a'")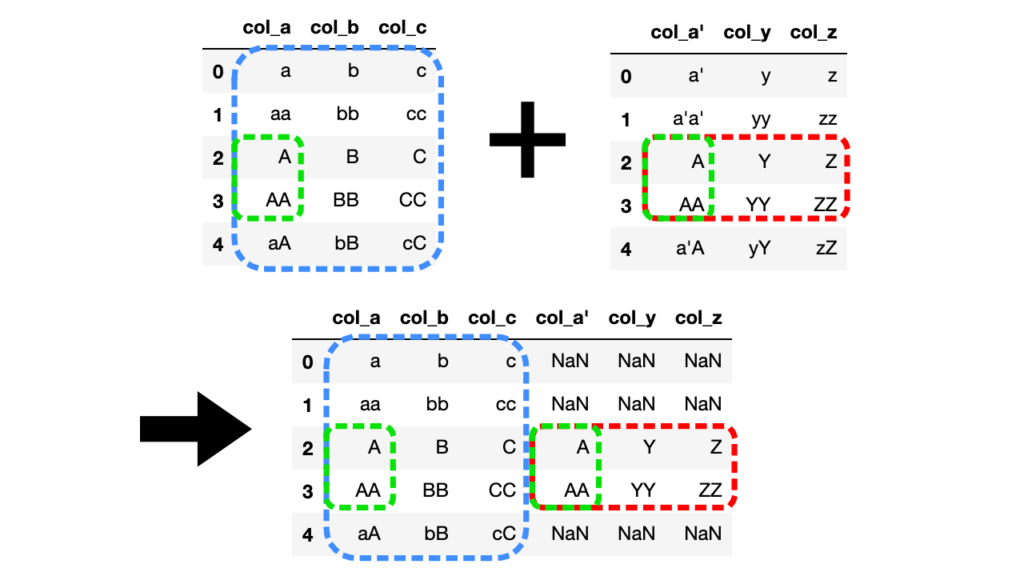
左側DataFrameを基準に列col_aと列col_a'で共通の値を持つ行を結合します。
共通の値を持たない行の値はNaN(Not a Number)で埋められます。
右外部結合(right)
右外部結合では右側DataFrameに左側DataFrameを足す形になります。
import pandas as pd
# 2つのDataFrameを作成(共通の列名を持たない)
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]})
df2 = pd.DataFrame({"col_a'": ["a'", "a'a'", "A", "AA", "a'A"], "col_y": ["y", "yy", "Y", "YY", "yY"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]})
# 右外部結合を指定(引数how="right")
## pd.merge()メソッドで結合
df3 = pd.merge(df1, df2, how="right", left_on="col_a", right_on="col_a'")
## pd.DataFrame.merge()メソッドで結合
df3 = df1.merge(df2, how="right", left_on="col_a", right_on="col_a'")
右側DataFrameを基準に列col_aと列col_a'で共通の値を持つ行を結合します。
共通の値を持たない行の値はNaN(Not a Number)で埋められます。
完全外部結合(outer)
完全外部結合では両方のDataFrameをそのまま足す形になります。
import pandas as pd
# 2つのDataFrameを作成(共通の列名を持たない)
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]})
df2 = pd.DataFrame({"col_a'": ["a'", "a'a'", "A", "AA", "a'A"], "col_y": ["y", "yy", "Y", "YY", "yY"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]})
# 完全外部結合を指定(引数how="outer")
## pd.merge()メソッドで結合
df3 = pd.merge(df1, df2, how="outer", left_on="col_a", right_on="col_a'")
## pd.DataFrame.merge()メソッドで結合
df3 = df1.merge(df2, how="outer", left_on="col_a", right_on="col_a'")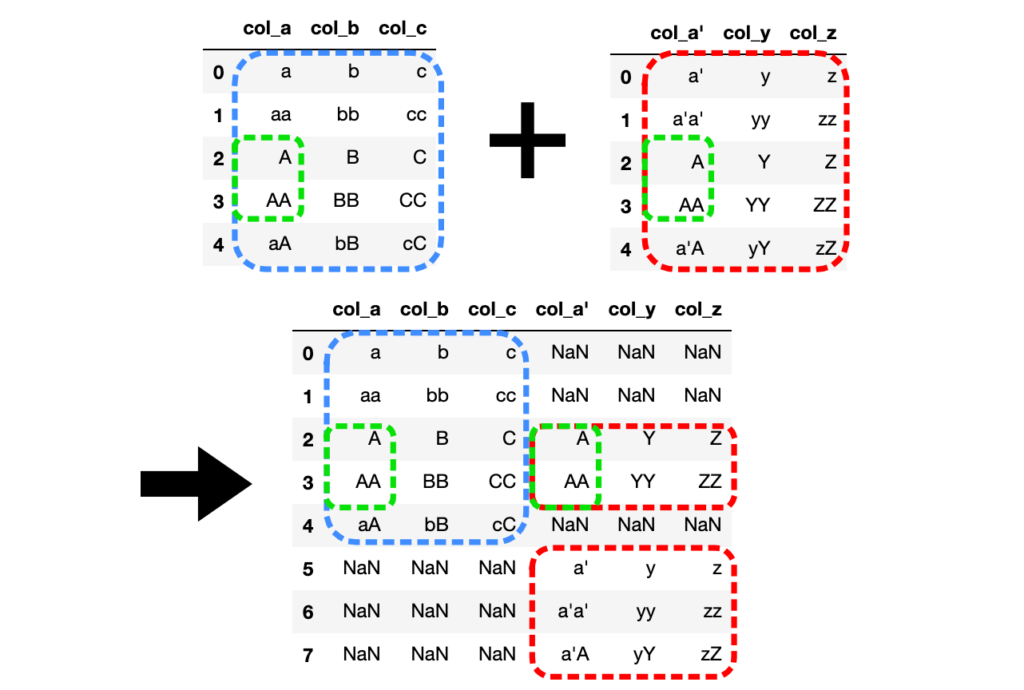
両方のDataFrameをに列col_aと列col_a'で共通の値を持つ行を結合し、
共通の値を持たない行の値はNaN(Not a Number)で埋められます。
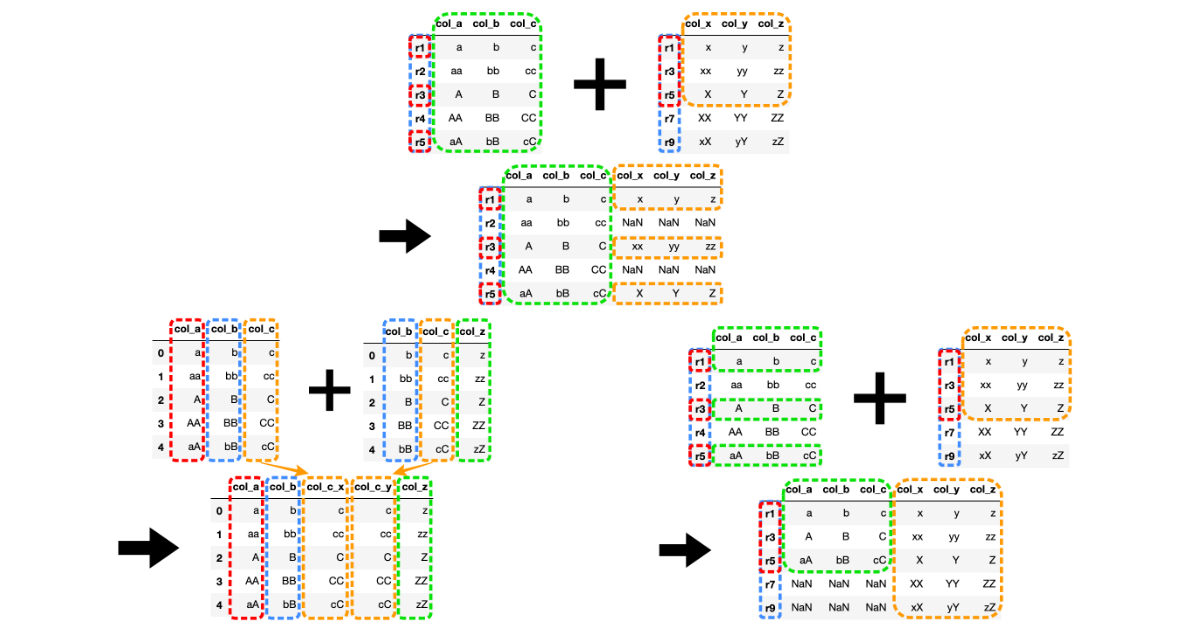
pd.DataFrame.join()の使い方
pd.DataFrame.join()ではDataFrameのインデックス(行名)をキーとして横方向に結合します。
import pandas as pd
# 2つのDataFrameを作成(共通のインデックス)
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]}, index=["r1", "r2", "r3", "r4", "r5"])
df2 = pd.DataFrame({"col_x": ["x", "xx", "X", "XX", "xX"], "col_y": ["y", "yy", "Y", "YY", "yY"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]}, index=["r1", "r2", "r3", "r4", "r5"])
# df1とdf2を結合
df3 = df1.join(df2)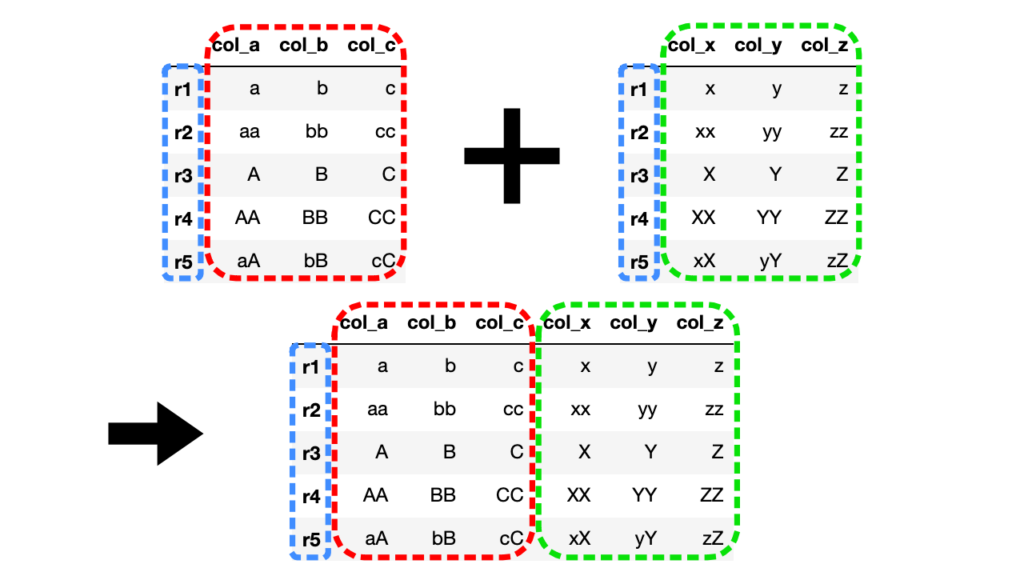
インデックス(行名)を基準に横方向からDataFrameが結合されています。
共通の列名を持つ場合の結合
結合するDataFrameで共通の列名を持っている場合、結合の左側と右側の共通列にサフィックスを指定する必要があります。
引数lsuffix, rsuffixをそれぞれ指定しないとエラーが出ます。
import pandas as pd
# 2つのDataFrameを作成(共通のインデックス & 共通の列col_c)
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]}, index=["r1", "r2", "r3", "r4", "r5"])
df2 = pd.DataFrame({"col_c": ["c", "cc", "C", "CC", "cC"], "col_y": ["y", "yy", "Y", "YY", "yY"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]}, index=["r1", "r2", "r3", "r4", "r5"])
# 左右のサフィックスを指定する必要がある
df3 = df1.join(df2, lsuffix="_A", rsuffix="_B")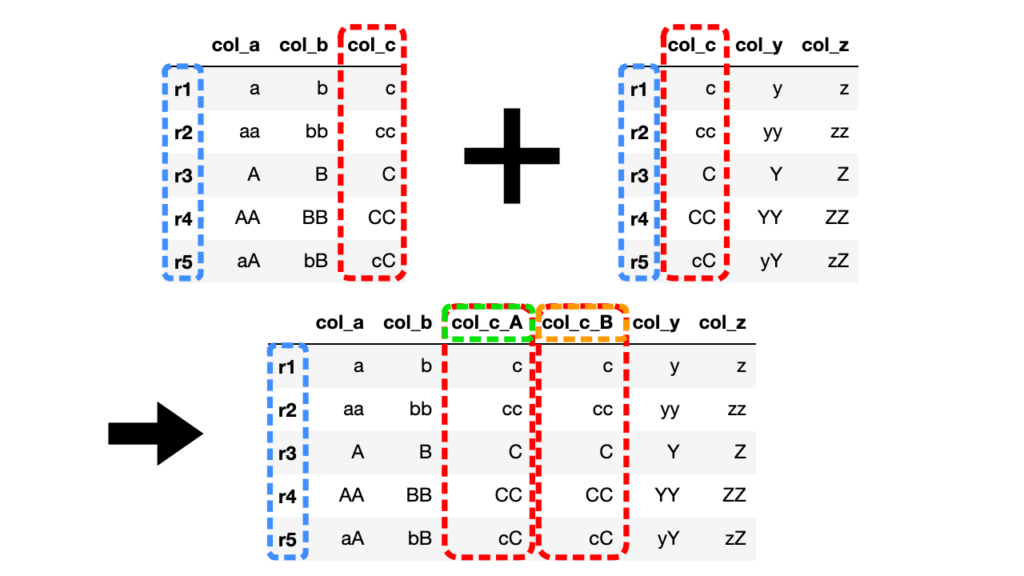
共通列col_cが左右それぞれ引数で指定したcol_c_A, col_c_Bとなって新たに生成されていることがわかります。
結合方法
pd.DataFrame.join()での結合方法は左外部結合がデフォルトになっています。
左外部結合(デフォルト)
右外部結合
完全外部結合
内部結合
左外部結合(left)
左外部結合では左側DataFrameに右側DataFrameを足す形になります。
import pandas as pd
# 2つのDataFrameを作成
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]}, index=["r1", "r2", "r3", "r4", "r5"])
df2 = pd.DataFrame({"col_x": ["x", "xx", "X", "XX", "xX"], "col_y": ["y", "yy", "Y", "YY", "yY"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]}, index=["r1", "r3", "r5", "r7", "r9"])
# 左外部結合(how="left")
df3 = df1.join(df2, how="left")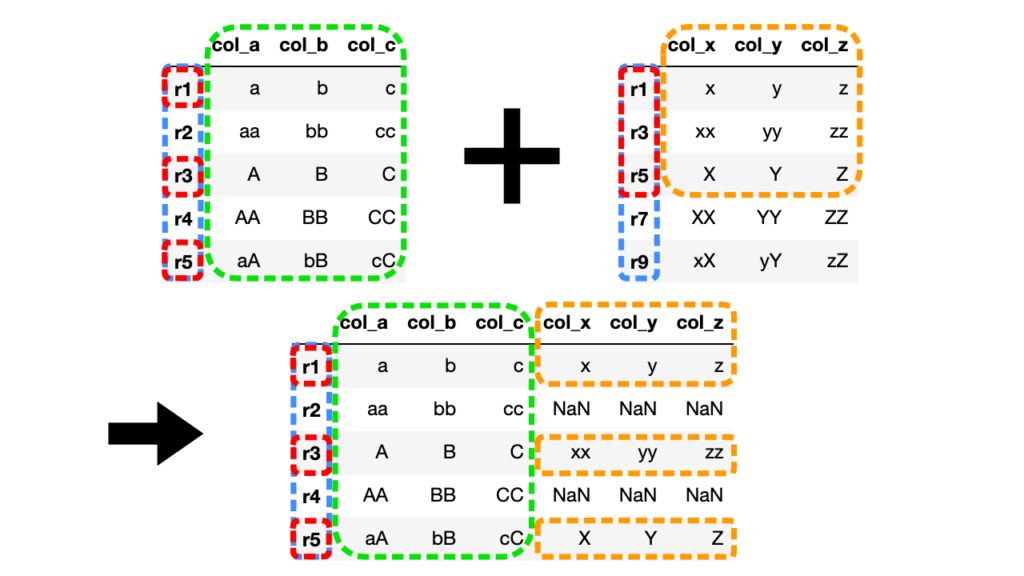
左側のDataFrameを基準に共通する値を持つ行だけが結合されます。
その他の値はNaN(Not a Number)で埋められます。
右外部結合(right)
右外部結合では右側DataFrameに左側DataFrameを足す形になります。
import pandas as pd
# 2つのDataFrameを作成
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]}, index=["r1", "r2", "r3", "r4", "r5"])
df2 = pd.DataFrame({"col_x": ["x", "xx", "X", "XX", "xX"], "col_y": ["y", "yy", "Y", "YY", "yY"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]}, index=["r1", "r3", "r5", "r7", "r9"])
# 右外部結合(how="right")
df3 = df1.join(df2, how="right")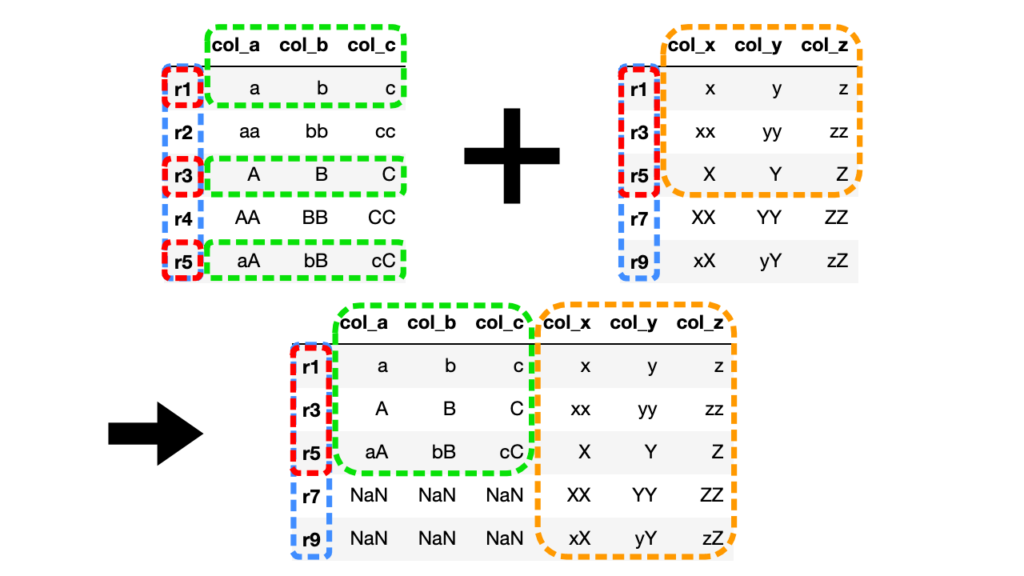
右側のDataFrameを基準に共通する値を持つ行だけが結合されます。
その他の値はNaN(Not a Number)で埋められます。
完全外部結合(outer)
完全外部結合では両方のDataFrameをそのまま足す形になります。
import pandas as pd
# 2つのDataFrameを作成
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]}, index=["r1", "r2", "r3", "r4", "r5"])
df2 = pd.DataFrame({"col_x": ["x", "xx", "X", "XX", "xX"], "col_y": ["y", "yy", "Y", "YY", "yY"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]}, index=["r1", "r3", "r5", "r7", "r9"])
# 完全外部結合(how="outer")
df3 = df1.join(df2, how="outer")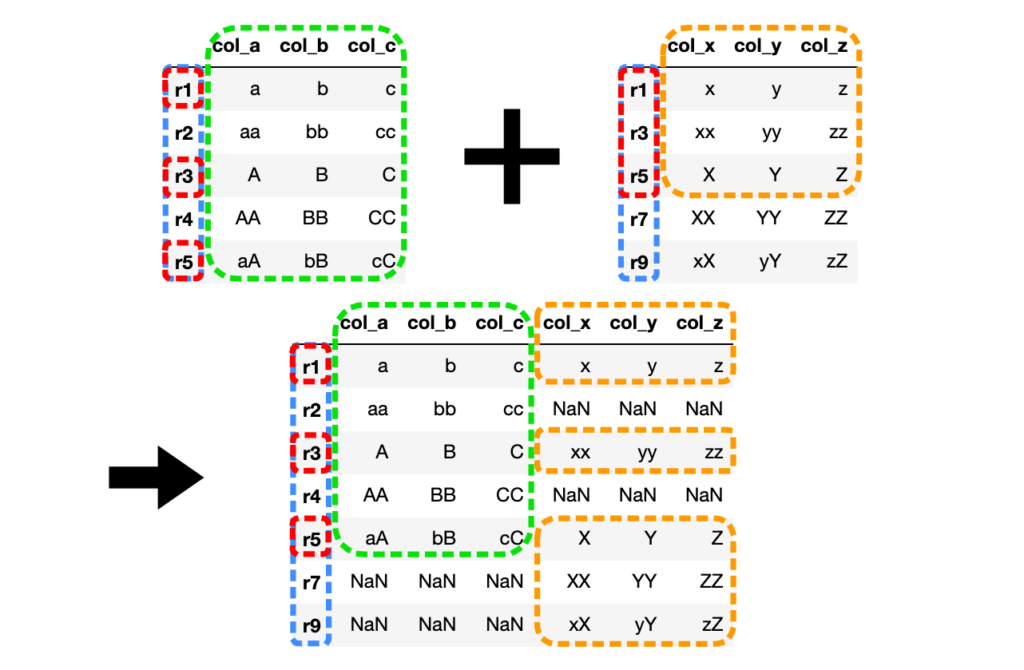
両方のDataFrameをにインデックス(行名)で共通の値を持つ行を結合し、
共通の値を持たない行の値はNaN(Not a Number)で埋められます。
内部結合(inner)
内部結合では左右のDataFrameの共通部分だけを残すように結合します。
import pandas as pd
# 2つのDataFrameを作成
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]}, index=["r1", "r2", "r3", "r4", "r5"])
df2 = pd.DataFrame({"col_x": ["x", "xx", "X", "XX", "xX"], "col_y": ["y", "yy", "Y", "YY", "yY"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]}, index=["r1", "r3", "r5", "r7", "r9"])
# 内部結合(how="inner")
df3 = df1.join(df2, how="inner")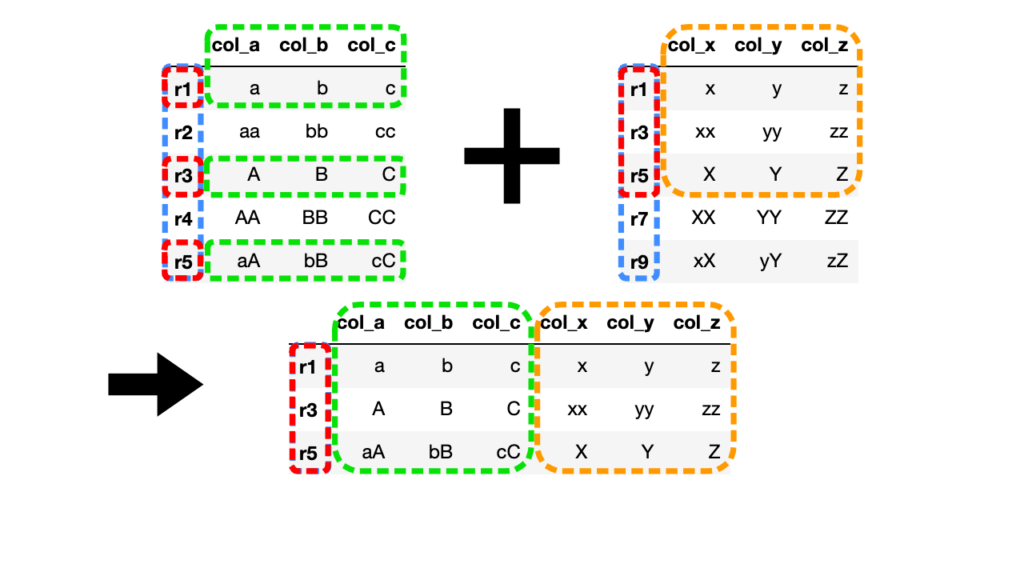
両方のDataFrameインデックスの共通する行のみを結合します。
左側DataFrameのキーを列名で指定(on)
左側DataFrameの結合キーをインデックスでなく、別の列名で指定できる。(左側DataFrameからしか選べない)
import pandas as pd
# 2つのDataFrameを作成
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_k": ["k", "kk", "K", "KK", "kK"]}, index=["r1", "r2", "r3", "r4", "r5"])
df2 = pd.DataFrame({"col_x": ["x", "xx", "X", "XX", "xX"], "col_y": ["y", "yy", "Y", "YY", "yY"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]}, index=["k'", "k'k'", "K", "KK", "k'K"])
# 左側DataFrameの結合キーを指定(on="col_k")
df3 = df1.join(df2, on="col_k")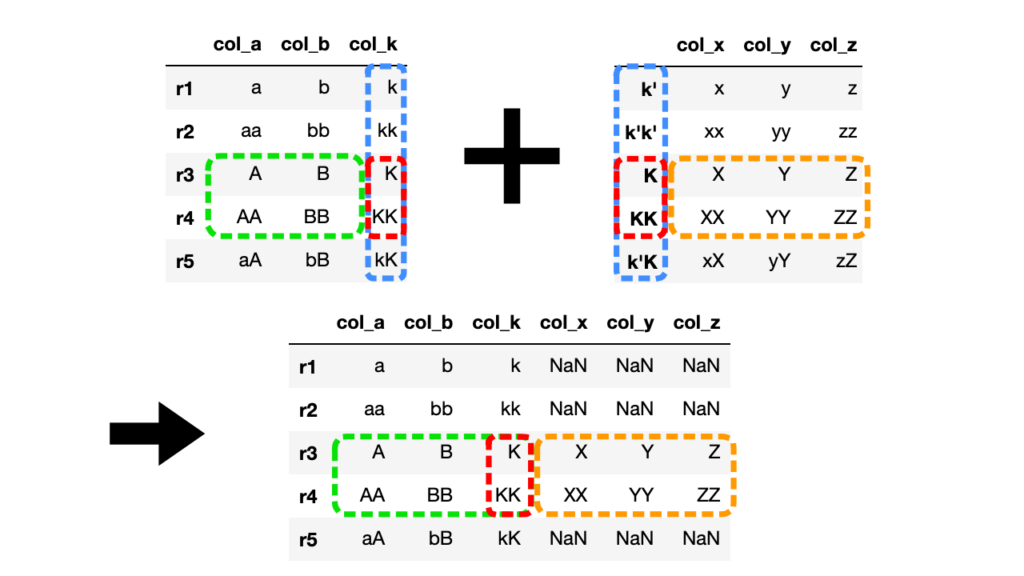
左側DataFrameの列名を指定して、右側DataFrameインデックスとの共通部分を結合します。
並び順をソート(sort)
結合後のDataFrameインデックスを昇順にソートすることができます。
import pandas as pd
# 2つのDataFrameを作成
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]}, index=["r3", "r5", "r4", "r1", "r2"])
df2 = pd.DataFrame({"col_x": ["x", "xx", "X", "XX", "xX"], "col_y": ["y", "yy", "Y", "YY", "yY"], "col_z": ["z", "zz", "Z", "ZZ", "zZ"]}, index=["r2", "r1", "r3", "r5", "r4"])
# 結合後のDataFrameインデックスを昇順にソート
df3 = df1.join(df2, sort=True)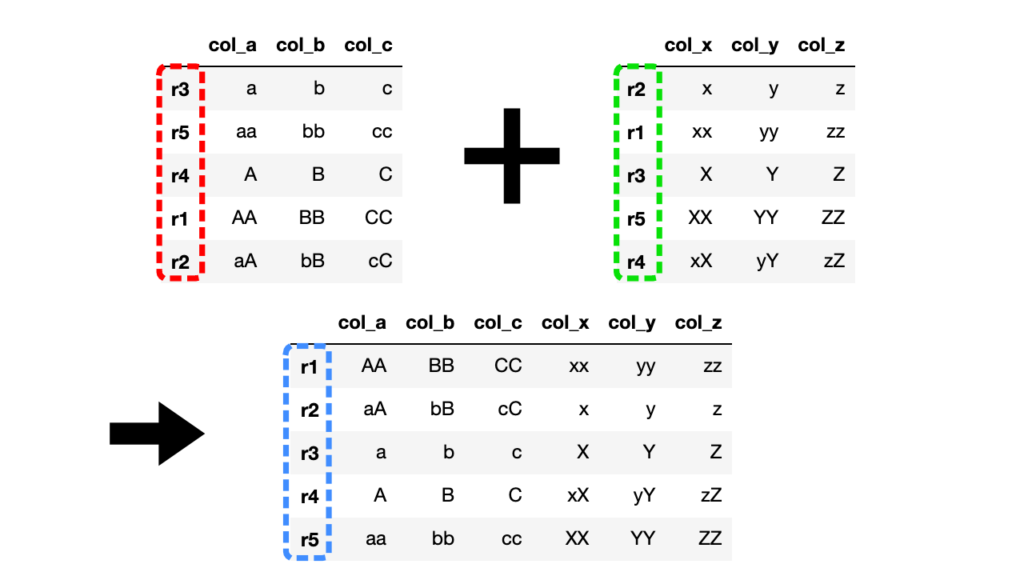
左右のDataFrameインデックスの並びがバラバラであっても、結合後にソートできます。
pd.concat()の使い方
pd.concat()では複数のDataFrameを連結して結合します。
引数objsに連結するDataFrameをリストもしくはタプルに入れて指定します。(objs=は省略するのが一般的)
import pandas as pd
# 2つのDataFrameを作成
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]})
df2 = pd.DataFrame({"col_c": ["c", "cc", "C", "CC", "cC"], "col_d": ["d", "dd", "D", "DD", "dD"], "col_e": ["e", "ee", "E", "EE", "eE"]})
# df1とdf2を連結
df3 = pd.concat(objs=[df1, df2])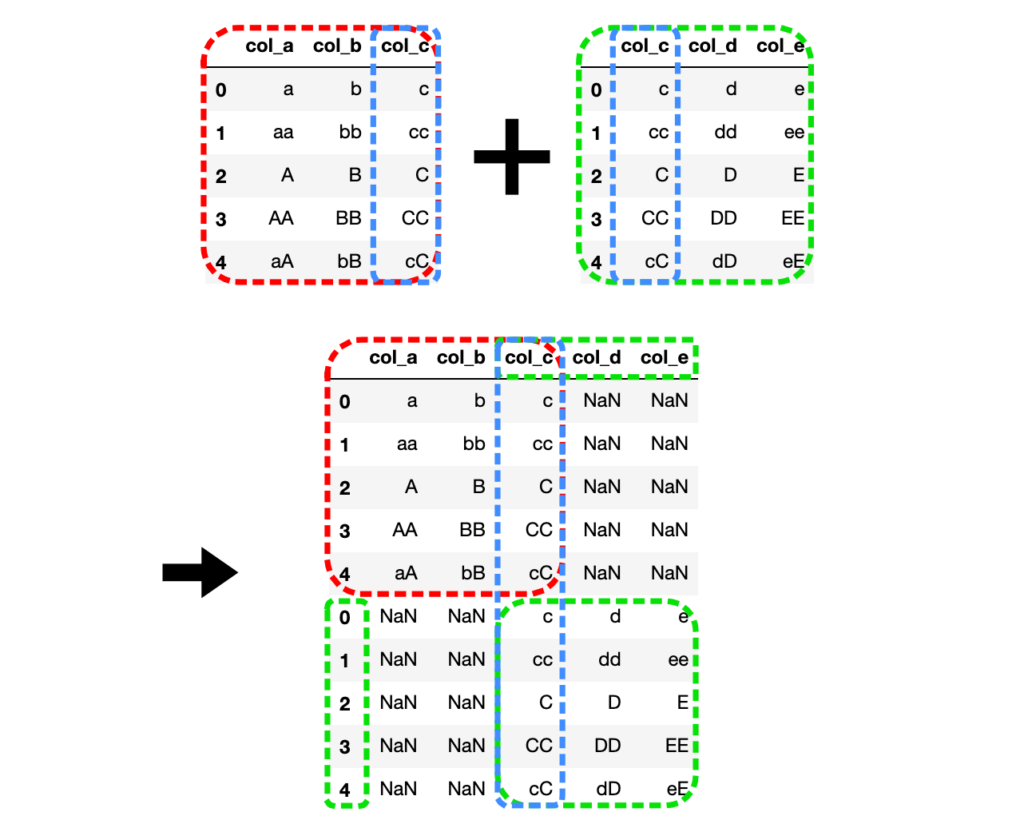
複数のDataFrameを共通の列名で結合して、縦方向(デフォルト)に連結します。
連結の軸方向を指定(axis)
デフォルトでは縦方向に結合しますが、横方向の連結が可能です。
引数axis=1を指定することで横方向に連結します。縦方向(デフォルト)は引数axis=0です。
import pandas as pd
# 2つのDataFrameを作成
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]})
df2 = pd.DataFrame({"col_c": ["c", "cc", "C", "CC", "cC"], "col_d": ["d", "dd", "D", "DD", "dD"], "col_e": ["e", "ee", "E", "EE", "eE"]})
# 横方向に連結(axis=1)
df3 = pd.concat([df1, df2], axis=1)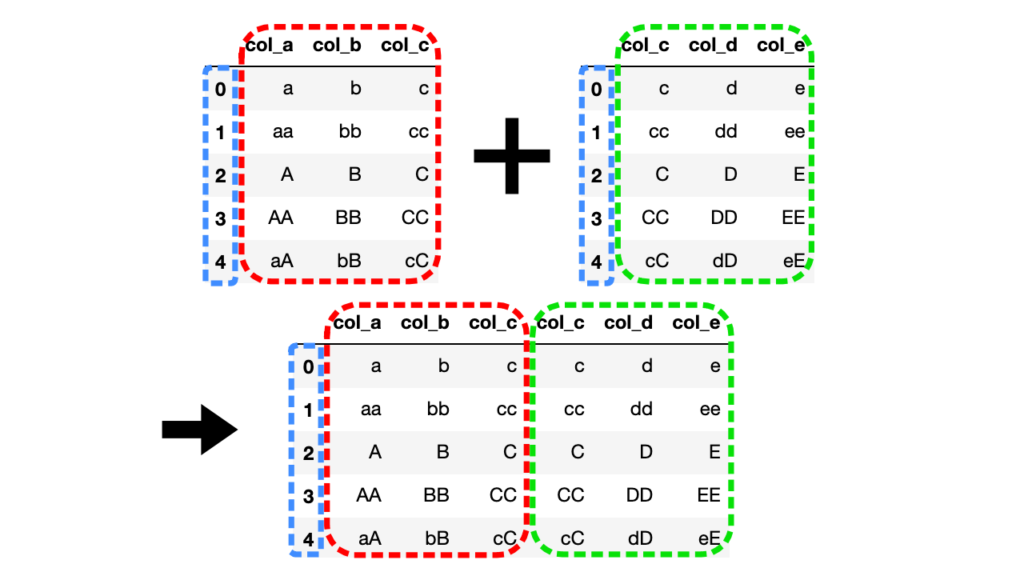
横方向に連結する場合、インデックスをキーとして共通の値を持つ列を結合します。
結合方法の指定(join)
連結するDataFrameのすべての値を結合(外部結合)するか、共通部分のみを結合(内部結合)するか指定できます。
外部結合
内部結合
結合方法を指定するには引数joinを指定します。デフォルトは引数join="outer"で外部結合です。
外部結合
import pandas as pd
# 2つのDataFrameを作成
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]})
df2 = pd.DataFrame({"col_c": ["c", "cc", "C", "CC", "cC"], "col_d": ["d", "dd", "D", "DD", "dD"], "col_e": ["e", "ee", "E", "EE", "eE"]})
# 外部結合(デフォルト)
df3 = pd.concat([df1, df2], join="outer")すべての値を結合して、共通しない部分はNaN(Not a Number)で埋められます。
内部結合
内部結合は引数join="inner"を指定します。
import pandas as pd
# 2つのDataFrameを作成
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]})
df2 = pd.DataFrame({"col_c": ["c", "cc", "C", "CC", "cC"], "col_d": ["d", "dd", "D", "DD", "dD"], "col_e": ["e", "ee", "E", "EE", "eE"]})
# 内部結合(join="inner")
df3 = pd.concat([df1, df2], join="inner")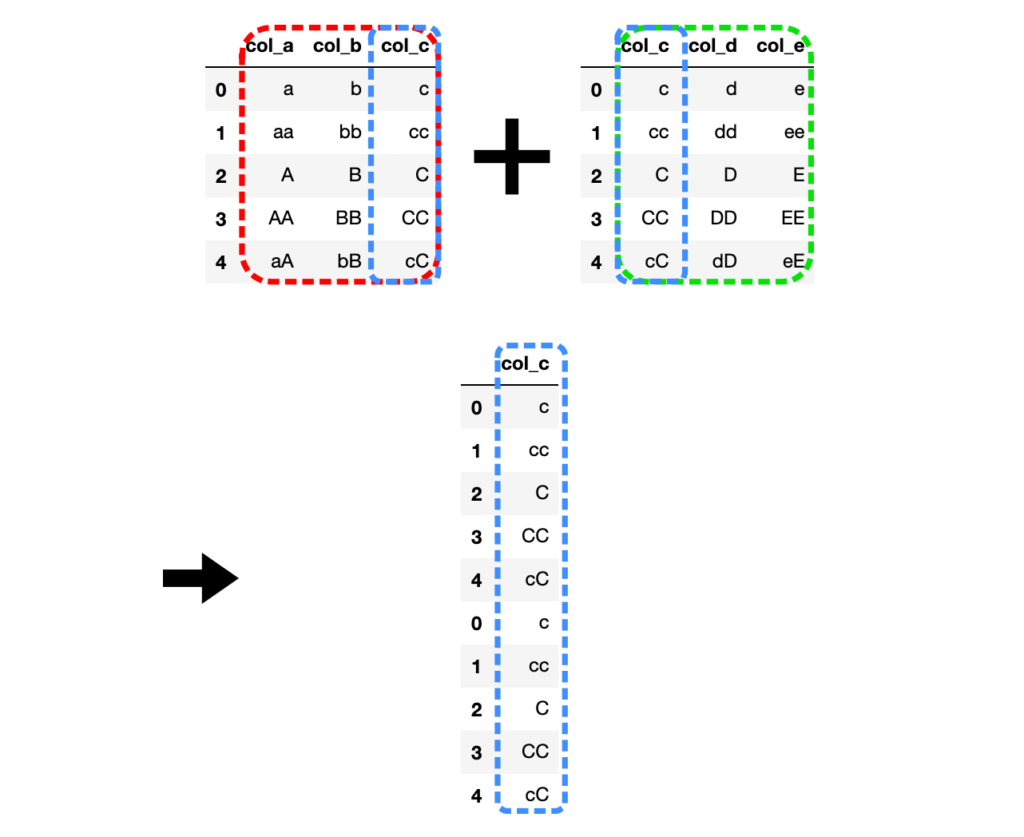
連結するDataFrameの共通する列名の値だけが結合されます。
インデックスを無視(ignore_index)
引数ignore_index=Trueを指定すると、DataFrameを連結後、連結の軸方向のインデックスを無視して0から値を振り直します。(デフォルトはFalse)
連結方向が縦方向の場合はDataFrameインデックスが、横方向の場合はDataFrameの列名が結合後に無視されて新しく0から順に値が振られます。
連結が縦方向
import pandas as pd
# 2つのDataFrameを作成
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]})
df2 = pd.DataFrame({"col_c": ["c", "cc", "C", "CC", "cC"], "col_d": ["d", "dd", "D", "DD", "dD"], "col_e": ["e", "ee", "E", "EE", "eE"]})
# 連結後、縦方向のインデックスを無視(ignore_index=True)
df3 = pd.concat([df1, df2], ignore_index=True, axis=0)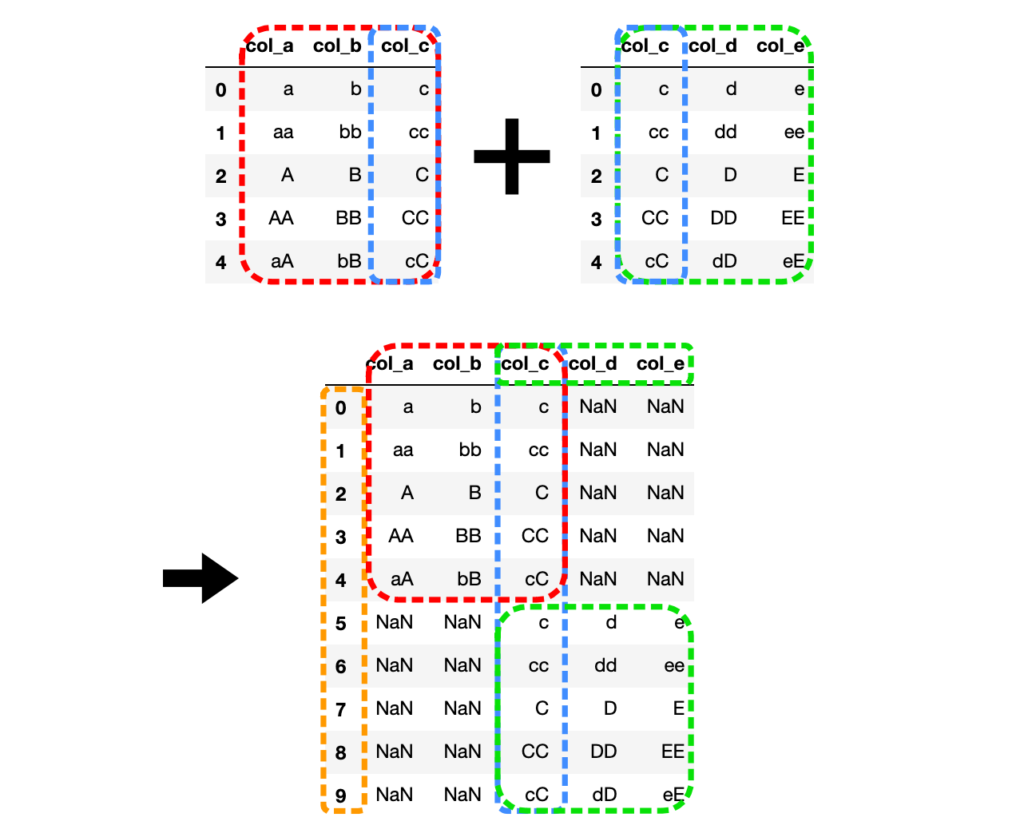
結合後のDataFrameインデックスが0から順に振られています。
連結が横方向
import pandas as pd
# 2つのDataFrameを作成
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]})
df2 = pd.DataFrame({"col_c": ["c", "cc", "C", "CC", "cC"], "col_d": ["d", "dd", "D", "DD", "dD"], "col_e": ["e", "ee", "E", "EE", "eE"]})
# df1とdf2を連結
df3 = pd.concat([df1, df2], ignore_index=True, axis=1)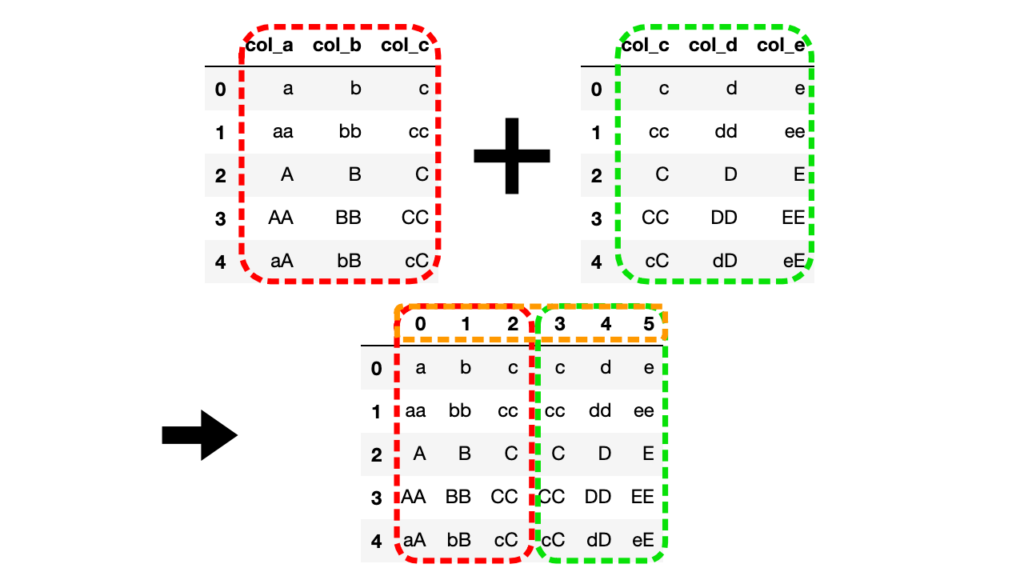
結合後のDataFrameの列名が0から順に値が振り直されています。
元のDataFrameの判別ラベルを付与(keys)
連結した後のDataFrameのインデックスに元のDataFrameのラベルをつけることができます。
引数keysに元のDataFrameを指すラベルを指定します。
連結が縦方向の場合はDataFrameインデックスの左に、横方向の場合はDataFrameの列名の上にラベルが表示されます。
連結が縦方向
import pandas as pd
# 2つのDataFrameを作成
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]})
df2 = pd.DataFrame({"col_c": ["c", "cc", "C", "CC", "cC"], "col_d": ["d", "dd", "D", "DD", "dD"], "col_e": ["e", "ee", "E", "EE", "eE"]})
# 元のDataFrameの判別ラベルを付与
df3 = pd.concat([df1, df2], keys=["No.1", "No.2"])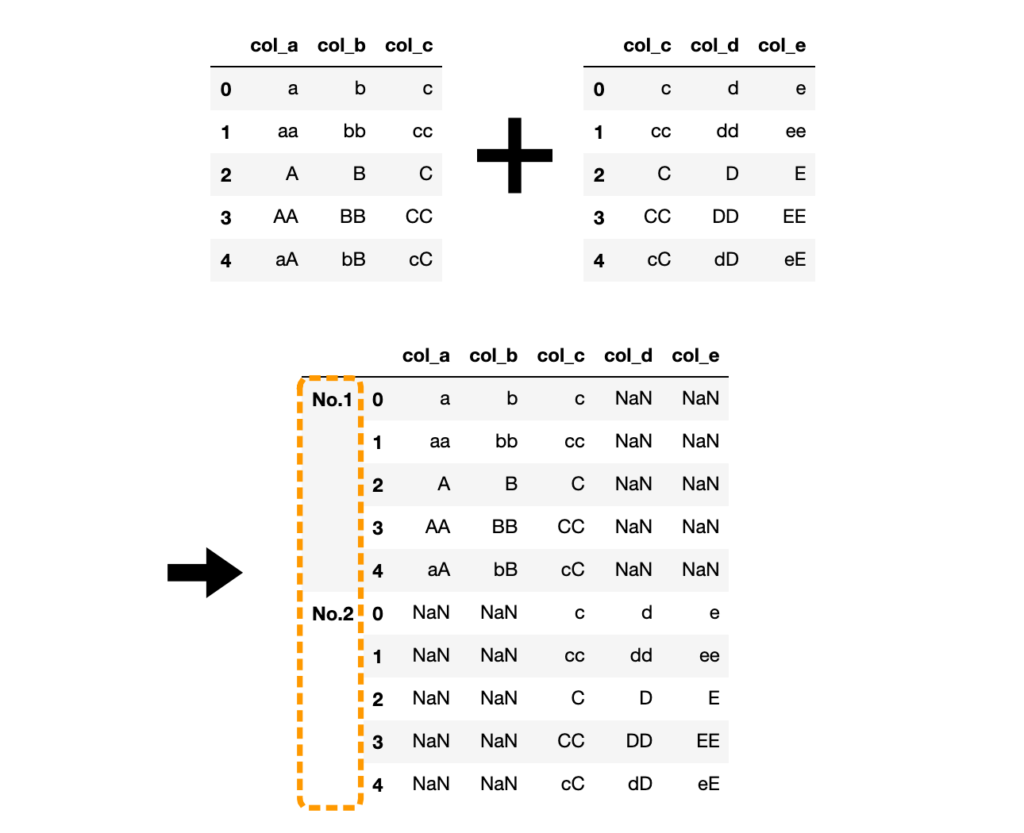
引数keysに指定した値がDataFrameインデックスの左に表示されます。
連結が横方向
import pandas as pd
# 2つのDataFrameを作成
df1 = pd.DataFrame({"col_a": ["a", "aa", "A", "AA", "aA"], "col_b": ["b", "bb", "B", "BB", "bB"], "col_c": ["c", "cc", "C", "CC", "cC"]})
df2 = pd.DataFrame({"col_c": ["c", "cc", "C", "CC", "cC"], "col_d": ["d", "dd", "D", "DD", "dD"], "col_e": ["e", "ee", "E", "EE", "eE"]})
# 元のDataFrameの判別ラベルを付与
df3 = pd.concat([df1, df2], keys=["No.1", "No.2"], axis=1)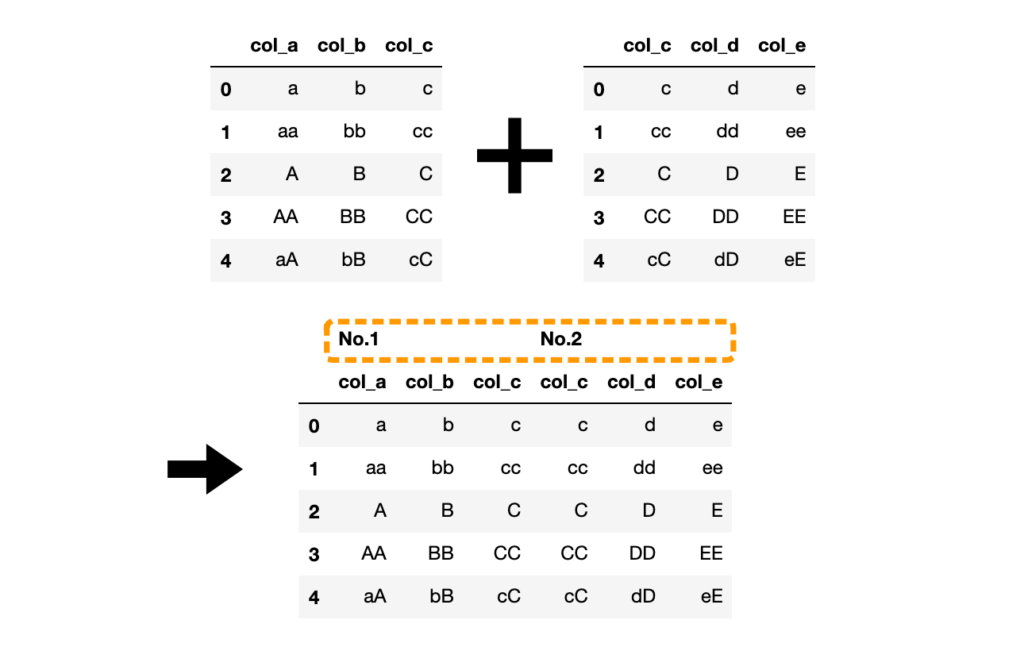
引数keysに指定した値がDataFrame列名の上に表示されます。
まとめ
今回はpandasのDataFrameを連結する方法を具体的に紹介しました。
複数のDataFrameを扱う際はとても便利ですので、ぜひ活用してみてください。