
本ページには PR が含まれます。

seleniumスクレイピングで
Webからcsvファイルダウンロードしたい…
今回はseleniumスクレイピングでWebからcsvファイルをダウンロードする方法をご紹介します。
サンプルコードを見ながらサクサク処理を試せるので、ぜひ参考にしてみてください。
seleniumライブラリの詳しい使い方はこちら

Pythonの実践的なWebスクレイピング技術について学びたいという方に向けてUdemy学習コースを公開しています。
\10/27(金)までの 90%OFFクーポンで Webスクレイピングを学べる!!/
30日間返金保証!
すぐにでもスクレイピング技術を活かせるようになりますよ!
ライブラリのインストール
はじめに今回使用するseleniumライブラリをインストールしておきましょう。
コマンドプロンプト(Windows)もしくはターミナル(macOS)で以下を実行します。
pip install seleniumコンソールの最終行に「Successfully Installed ~~~」と表示されればインストールは成功です。
ダウンロード操作をふまえたwebdriverの設定
Webからのダウンロード処理がある場合、seleniumでのwebdriverに追加設定が必要になります。
サンプルコード
import time
import glob
import shutil
from pathlib import Path
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
############### ダウンロード機能の追加 ###############
# ダウンロードファイルの一時保存フォルダを作成(カレントディレクトリに「tmp」フォルダを作成)
tmp_dir = Path(Path.cwd(), "tmp")
tmp_dir.mkdir(exist_ok=True, parents=True)
# webdriverにオプションを追加
options = Options()
prefs = {"download.default_directory": str(tmp_dir)}
options.add_experimental_option("prefs", prefs)
# chromedriverのパスを指定
driver_path = "/Users/「PCのユーザ名」/Downloads/chromedriver"
chrome_service = Service(executable_path=driver_path)
# 追加したオプションを設定してwebdriverを起動
driver = webdriver.Chrome(service=chrome_service, options=options)Webページにアクセス
まずはcsvファイルをダウンロードする先にWebページにアクセスします。
seleniumでのWebページへのアクセス
driver.get(url="アクセス先のURL")
ここでは例としてe-Statsという政府統計のオープンデータを扱うポータルサイトを使用します。
サンプルコード
import time
import glob
import shutil
from pathlib import Path
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
tmp_dir = Path(Path.cwd(), "tmp")
tmp_dir.mkdir(exist_ok=True, parents=True)
options = Options()
prefs = {"download.default_directory": str(tmp_dir)}
options.add_experimental_option("prefs", prefs)
driver_path = "/Users/「PCのユーザ名」/Downloads/chromedriver"
chrome_service = Service(executable_path=driver_path)
driver = webdriver.Chrome(service=chrome_service, options=options)
############### ここからWebページへのアクセス処理 ###############
# e-Statsのcsvダウンロードページにアクセス
url = "https://www.e-stat.go.jp/stat-search/files?page=1&layout=datalist&toukei=00200521&tstat=000001011777&cycle=0&tclass1=000001094741&tclass2val=0"
driver.get(url=url)実行結果
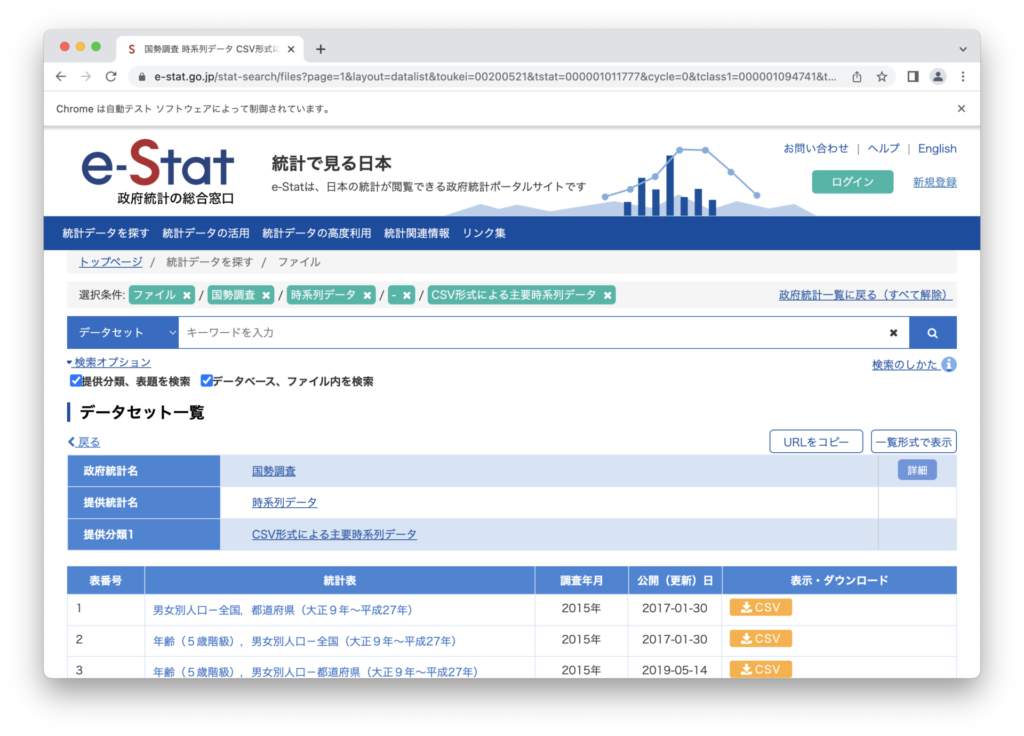
ダウンロード「ボタンorリンク」の特定
Webページにアクセスしたら、csvダウンロードボタンをseleniumで探索します。
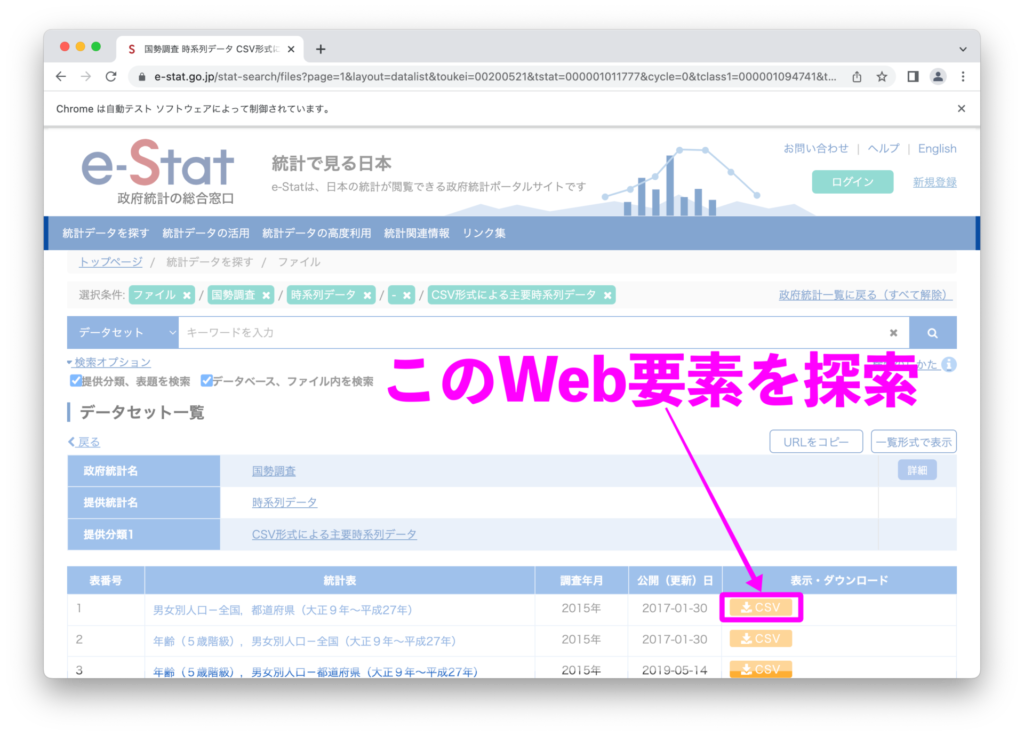
はじめにブラウザをアクティブにして「F12」キーを押下し、検証機能を開きましょう。
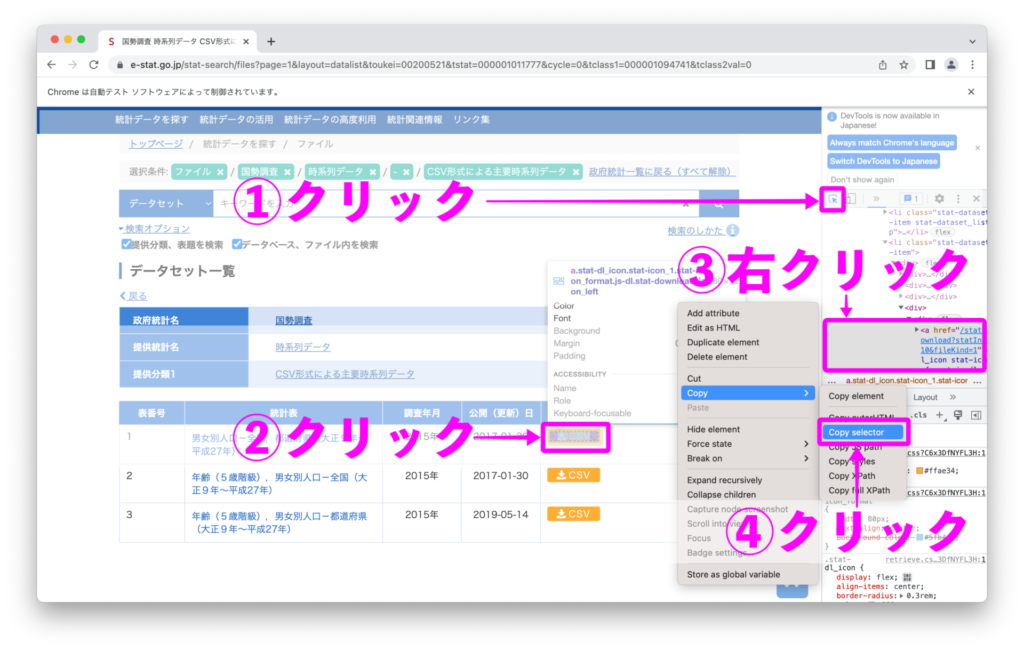
検証機能を使って上図のようにして「CSSセレクタ」をコピーします。
Web上の要素をCSSセレクタを用いた探索
driver.find_element(by=By.CSS_SELECTOR, value=任意のCSSセレクタ)
サンプルコード
import time
import glob
import shutil
from pathlib import Path
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
tmp_dir = Path(Path.cwd(), "tmp")
tmp_dir.mkdir(exist_ok=True, parents=True)
options = Options()
prefs = {"download.default_directory": str(tmp_dir)}
options.add_experimental_option("prefs", prefs)
driver_path = "/Users/「PCのユーザ名」/Downloads/chromedriver"
chrome_service = Service(executable_path=driver_path)
driver = webdriver.Chrome(service=chrome_service, options=options)
url = "https://www.e-stat.go.jp/stat-search/files?page=1&layout=datalist&toukei=00200521&tstat=000001011777&cycle=0&tclass1=000001094741&tclass2val=0"
driver.get(url=url)
##################### ここからWeb要素の探索 #####################
# コピーしたCSSセレクタを文字列に格納
selector = "body > div.dialog-off-canvas-main-canvas > div > main > div.row.l-estatRow > section > div.region.region-content > div > div > div.stat-content.fix > section > section > div > div.stat-dataset_list > div > article:nth-child(1) > div > ul > li:nth-child(2) > div > div:nth-child(4) > div > a"
element = driver.find_element(by=By.CSS_SELECTOR, value=selector)
# 取得したWeb要素のHTMLを表示
print(element.get_attribute("outerHTML"))実行結果
'<a href="/stat-search/file-download?statInfId=000031524010&fileKind=1" class="stat-dl_icon stat-icon_1 stat-icon_format js-dl stat-download_icon_left" data-file_id="000007847517" data-release_count="2" data-file_type="CSV" tabindex="22">\n<span class="stat-dl_text">CSV</span>\n</a>'ダウンロードの実行(ダウンロード待機処理)
Web要素を特定できたので、seleniumでボタンをクリックしてCSVファイルをPCにダウンロードしていきましょう。
単にseleniumで「ダウンロードボタン」をクリックすればOKですが、ダウンロードが完了するまで待機した方がselenium操作が安定します。
Chrome上でファイルをダウンロードすると、「.crdownload」という拡張子ファイルが一時的に生成されます。
この「.crdownload」が消えたかどうかで、ダウンロード完了を判定できます。
サンプルコード
import time
import glob
import shutil
from pathlib import Path
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
tmp_dir = Path(Path.cwd(), "tmp")
tmp_dir.mkdir(exist_ok=True, parents=True)
options = Options()
prefs = {"download.default_directory": str(tmp_dir)}
options.add_experimental_option("prefs", prefs)
driver_path = "/Users/「PCのユーザ名」/Downloads/chromedriver"
chrome_service = Service(executable_path=driver_path)
driver = webdriver.Chrome(service=chrome_service, options=options)
url = "https://www.e-stat.go.jp/stat-search/files?page=1&layout=datalist&toukei=00200521&tstat=000001011777&cycle=0&tclass1=000001094741&tclass2val=0"
driver.get(url=url)
selector = "body > div.dialog-off-canvas-main-canvas > div > main > div.row.l-estatRow > section > div.region.region-content > div > div > div.stat-content.fix > section > section > div > div.stat-dataset_list > div > article:nth-child(1) > div > ul > li:nth-child(2) > div > div:nth-child(4) > div > a"
element = driver.find_element(by=By.CSS_SELECTOR, value=selector)
##################### ダウンロード処理の実行 #####################
#ダウンロードボタンをクリック
element.click()
# 一時保存フォルダ内に".crdownload"の拡張子ファイルがある場合は待機
timeout_sec = 3
success_flg = True
while glob.glob(str(tmp_dir) + "/*.crdownload") != []:
time.sleep(1)
timeout_sec -= 1
if timeout_sec < 0:
# ダウンロード失敗タイムアウト
shutil.rmtree(tmp_dir)
success_flg = False
break
if success_flg:
time.sleep(1)
# 正常にダウンロード成功したら、正規保存フォルダを作成して
# ダウンロードしたすべてのファイルを一時保存フォルダから正規保存へ移動
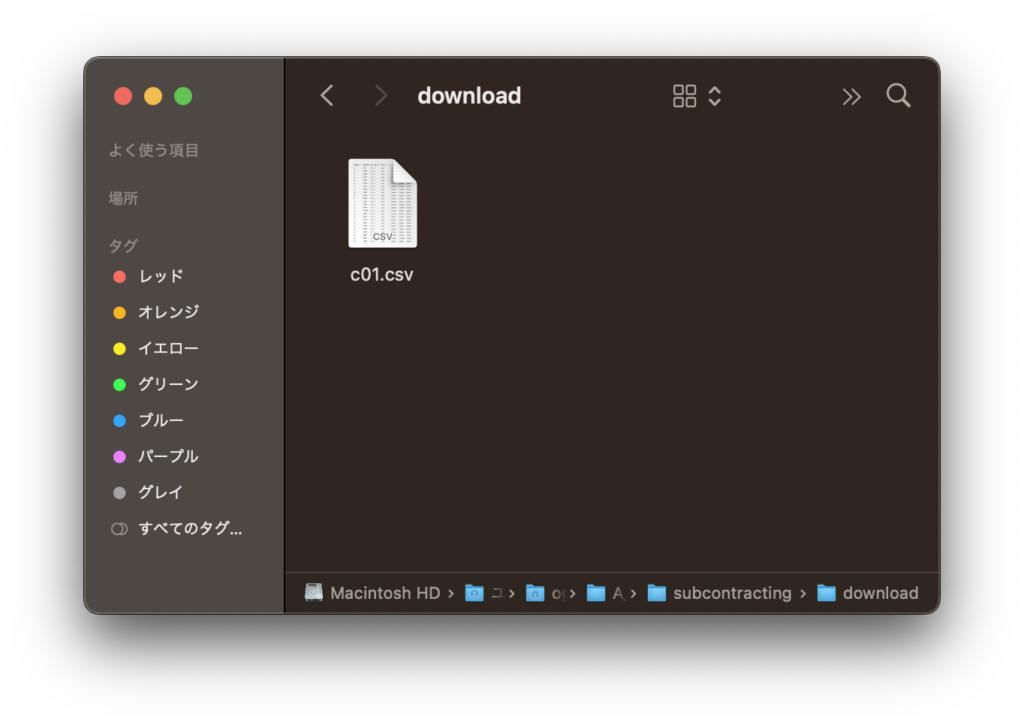
download_dir = Path(Path.cwd(), "download")
download_dir.mkdir(exist_ok=True, parents=True)
for file in glob.glob(str(tmp_dir) + "/*.*"):
shutil.move(file, Path.cwd())
# 一時保存フォルダを削除
shutil.rmtree(tmp_dir)
driver.quit()実行結果
まとめ
本記事では、seleniumスクレイピングでWebからcsvファイルをダウンロードする方法をご紹介しました。
Webスクレイピングをマスターすると、情報収集が圧倒的にラクになります。
- 仕事で毎日行うデータ収集
- 予約サービスへの自動登録・応募
- ショッピングサイトの価格監視
などなど、さまざまな分野で応用できます。
Pythonの実践的なWebスクレイピング技術について学びたいという方に向けてUdemy学習コースを公開しています。
\10/27(金)までの 90%OFFクーポンで Webスクレイピングを学べる!!/
30日間返金保証!
すぐにでもスクレイピング技術を活かせるようになりますよ!
Webスクレイピングで日々の作業を自動化し、より有意義な時間を増やしましょう!!
他にもPythonのWebスクレイピング技術の活用方法を紹介しているので、ぜひ参考にしてみてください。


